python爬虫
1771 浏览 7 years, 10 months
4.4 爬虫自动登录readthedocs.org
版权声明: 转载请注明出处 http://www.codingsoho.com/密码明码
一.使用Fiddler观察数据传输 设置host过滤:readthedocs.org
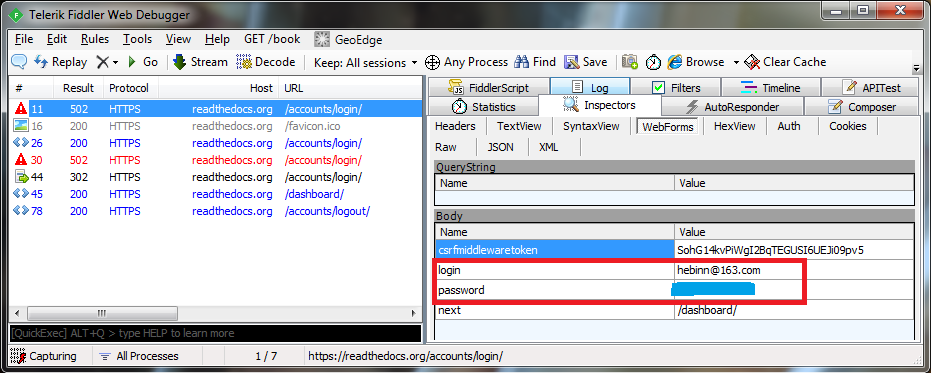
发送的Raw Header信息
POST /accounts/login/ HTTP/1.1
Accept: text/html, application/xhtml+xml, */*
Referer: [https://readthedocs.org/accounts/login/](https://readthedocs.org/accounts/login/)
Accept-Language: zh-CN
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Host: readthedocs.org
Content-Length: 94
Connection: Keep-Alive
Cache-Control: no-cache
Cookie: csrftoken=YjesStLtCe65rWYZjzgmpexDhJyNn3iD; __utma=263995919.1003316899.[1471389439.1471389439.1471391854.2](1471389439.1471389439.1471391854.2); __utmc=263995919; __utmz=263995919.1471389439.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmb=[263995919.3.10.1471391854](263995919.3.10.1471391854); __utmt=1
Response Header信息
HTTP/1.1 302 FOUND
Server: nginx/1.10.0 (Ubuntu)
Date: Tue, 16 Aug 2016 12:13:25 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Vary: Cookie, Accept-Language
Location: [https://readthedocs.org/dashboard/](https://readthedocs.org/dashboard/)
Content-Language: en
Set-Cookie: csrftoken=GNuoD2koNdCV1VerXkmShKGlS6OinMwc; expires=Tue, 15-Aug-2017 12:13:25 GMT; httponly; Max-Age=31449600; Path=/
Set-Cookie: sessionid=55dt7x3gmta4vrdd3lf13b0dpxgvkh6p; Domain=readthedocs.org; httponly; Path=/
Set-Cookie: messages="b2e9868c5aed331f8de2aa7f6b828b30b0a4a318$[[\"__json_message\"\0540\05425\054\"Successfully signed in as hebinn.\"]]"; Domain=readthedocs.org; httponly; Path=/
X-Frame-Options: DENY
X-Deity: web01
Content-Length: 0
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
pro = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(pro)
访问链接(包含Request Header),这儿访问主页的目的是为了得到csrftoken,每次访问都会在response cookie返回这个值,下一次request访问时会用到这个值.
url = '[https://readthedocs.org](https://readthedocs.org)'
op = opener.open(url)
cookies=op.headers["Set-cookie"]
cookie=cookies[cookies.index("csrftoken="):]
csrftoken = cookie[10:cookie.index(";")+0]
print csrftoken
访问登录链接
url = '[https://readthedocs.org/accounts/login/](https://readthedocs.org/accounts/login/)'
webheader = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
#'Content-Type': 'application/x-www-form-urlencoded',
#'Cache-Control': 'no-cache',
'Accept-Language': 'zh-cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
#'Accept-Encoding': 'gzip, deflate',
'Referer': '[https://readthedocs.org/accounts/login/](https://readthedocs.org/accounts/login/)',
#'Origin': '[https://readthedocs.org](https://readthedocs.org)',
'Host': 'readthedocs.org'
}
id = 'hebinn@163.com'
password = ''
postDict = {
'login': id,
'csrfmiddlewaretoken':csrftoken,
'password': password,
'next': '/dashboard/'
}
postData = urllib.urlencode(postDict).encode()
request = urllib2.Request(url, headers=webheader, data=postData)
try:
op = opener.open(request)
except urllib2.HTTPError, e:
print e.reason
print e.fp.read()
data = op.read()
import sys
data = data.decode('utf-8').encode(sys.getfilesystemencoding())
print(data)
有的时候数据需要解压缩
import gzip
from StringIO import StringIO
......
op = opener.open(url, postData)
data = op.read()
if op.info().get('Content-Encoding')== 'gzip':
buf = StringIO(op.read())
f = gzip.GzipFile(fileobj=buf)
data = f.read()
#Python3.x
data = ungzip(data)
有的数据post的时候需要从前面一次访问中拿某些参数
import re
def getcsrftoken(data):
cer = re.compile('csrftoken=(.*);', flags = 0)
strlist = cer.findall(data)
return strlist[0]
url = '[https://readthedocs.org](https://readthedocs.org)'
op = opener.open(url)
data = op.read()
if op.info().get('Content-Encoding')== 'gzip':
data = ungzip(data)
csrftoken = getcsrftoken(data.decode())