python爬虫
1334 浏览 7 years, 10 months
4.1 简单爬虫网页访问
版权声明: 转载请注明出处 http://www.codingsoho.com/简单爬虫网页访问
import urllib
import sys
url = "[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)?ac=article&at=read&did=444"
webPage=urllib.urlopen(url)
data = webPage.read()
data = data.decode('utf-8').encode(sys.getfilesystemencoding())
设置代理的代码如下(便于fiddler抓包分析)
import urllib2
import sys
url = "[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)?ac=article&at=read&did=444"
proxy = urllib2.ProxyHandler({'http': '[127.0.0.1:8888](127.0.0.1:8888)'})
opener = urllib2.build_opener(proxy)
urllib2.install_opener(opener)
webPage=urllib2.urlopen(url)
data = webPage.read()
data = data.decode('utf-8').encode(sys.getfilesystemencoding())
print(data)
print(type(webPage))
print(webPage.geturl())
print(webPage.info())
输出结果如下
>>> print(type(webPage))
<type 'instance'>
>>> print(webPage.geturl())
[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)?ac=article&at=read&did=444
>>> print(webPage.info())
Date: Thu, 11 Aug 2016 10:38:48 GMT
Server: Apache/2.4.10 (Win32) OpenSSL/1.0.1h
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
>>> print(webPage.getcode())
200
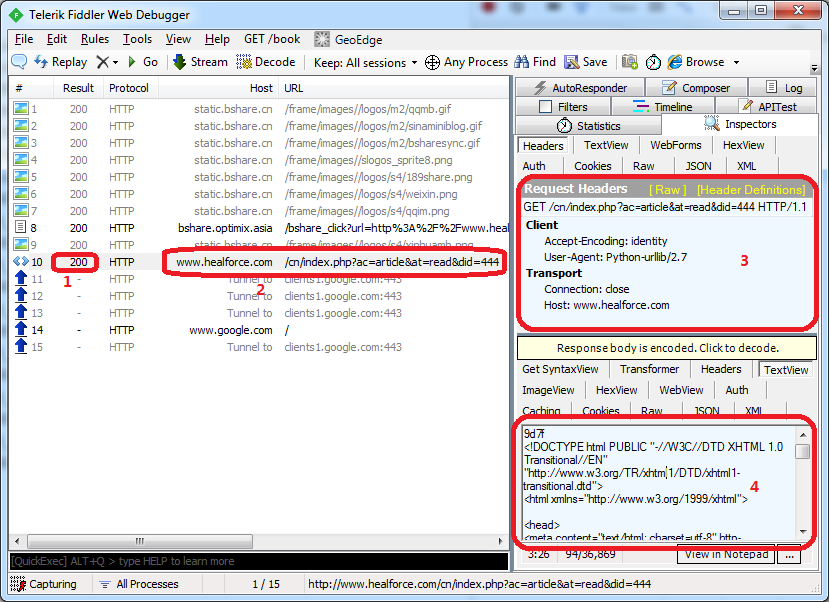
用Fiddler来抓取数据分析
- 200表示访问成功
- 访问的地址
- Python生成的请求表头
- 响应返回的html,这个跟print(data)返回的是一样的