python爬虫
1801 浏览 7 years, 10 months
3.3 urllib2
版权声明: 转载请注明出处 http://www.codingsoho.com/urllib
https://docs.python.org/2.7/library/urllib2.html
在Python3中,urllib拆分进了urllib.request, urllib.error
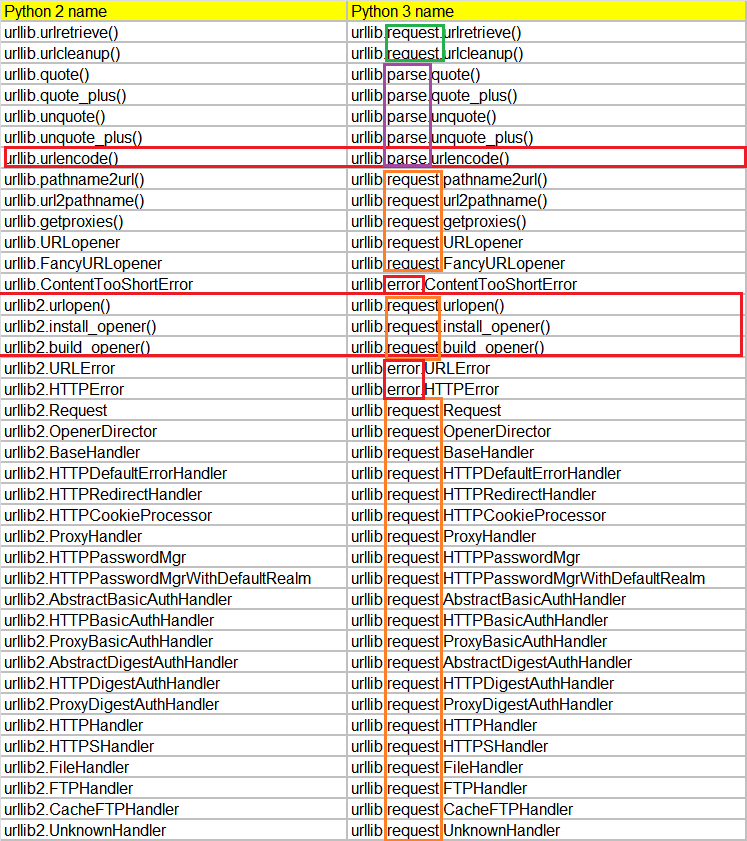
urlopen
import urllib2
f = urllib2.urlopen('[https://readthedocs.org/](https://readthedocs.org/)')
print f.read(100)
urlopen函数返回包含三个方法
- geturl() — 返回资源获取的实际URL,一般用于判断是否发生了重定向
- info() — 返回元信息,比如头
- getcode() — 返回响应状态码.
print(type(f))
# <type 'instance'>
print(f.geturl())
# [https://readthedocs.org/](https://readthedocs.org/)
print(f.info())
'''
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
Content-Language: en
Vary: Cookie, Accept-Language
Server: nginx/1.14.0 (Ubuntu)
Set-Cookie: csrftoken=yBaXxLTZf09KLttdND8oTYskZii4wytn; expires=Tue, 23-Oct-2018 01:02:42 GMT; HttpOnly; Max-Age=2592000; Path=/
X-Frame-Options: DENY
X-Deity: web02
Date: Sun, 23 Sep 2018 01:02:41 GMT
Connection: close
'''
print(f.getcode())
# 200
Handler
ProxyHandler
通过ProxyHandler添加代理
import urllib2
proxy_handler = urllib2.ProxyHandler({'http': '[127.0.0.1:8888](127.0.0.1:8888)'})
opener = urllib2.build_opener(proxy_handler)
f = opener.open('[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)')
print f.read(100)
可以通过urllib2.install_opener把这个opener安装为全局opener。
除非你希望urlopen默认使用这个opener,否则你直接使用OpenerDirector.open()代替 urlopen()就可以了
import urllib2
proxy_handler = urllib2.ProxyHandler({'http': '[127.0.0.1:8888](127.0.0.1:8888)'})
opener = urllib2.build_opener(proxy_handler)
urllib2.install_opener(opener)
f=urllib2.urlopen('[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)')
print f.read()
ProxyBasicAuthHandler
如何代理需要authentication的话,可以通过下列方法去添加ProxyBasicAuthHandler,后续更新
proxy_auth_handler = urllib2.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib2.build_opener(proxy_handler, proxy_auth_handler)
HTTPRedirectHandler
urllib2 默认情况下会针对 3xx HTTP 返回码自动进行 Redirect 动作,无需人工配置。
要检测是否发生了 Redirect 动作,只要检查一下 Response 的 URL 和 Request 的 URL 是否一致就可以了。
import urllib2
response = urllib2.urlopen('[https://readthedocs.org](https://readthedocs.org)')
redirected = response.geturl() == '[https://readthedocs.org](https://readthedocs.org)'
如果不想自动 Redirect,除了使用更低层次的 httplib 库之外,还可以使用自定义的 HTTPRedirectHandler 类。
import urllib2
class RedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(self, req, fp, code, msg, headers):
pass
def http_error_302(self, req, fp, code, msg, headers):
pass
opener = urllib2.build_opener(RedirectHandler)
opener.open('[https://readthedocs.org](https://readthedocs.org)')
Processor
HTTPCookieProcessor
import urllib2
import cookielib
cj = cookielib.CookieJar()
pro = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(pro)
url = '[https://readthedocs.org](https://readthedocs.org)'
op = opener.open(url)
cookies=op.headers["Set-cookie"]
python3
#Python3.x
import http.cookiejar
cj = http.cookiejar.CookieJar()
import urllib.request
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
Request
urlopen
import urllib2
url = "[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)?ac=article&at=read&did=444"
request = urllib2.Request(url)
op=urllib2.urlopen(request)
ftp可以同样方式访问
url = "ftp://3gpp.org/"
HTTP data
有时候希望发送一些数据
postDict = {
'login': id,
'csrfmiddlewaretoken':csrftoken,
'password': password,
'next': '/dashboard/'
}
data = urllib.urlencode(postDict)
request = urllib2.Request(url, data)
op=urllib2.urlopen(request)
HTTP header
import urllib2
url = "[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)?ac=article&at=read&did=444"
webheader = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Host': 'www.healforce.com',
}
opener = urllib2.build_opener()
urllib2.install_opener(opener)
request = urllib2.Request(url,headers=webheader)
op=urllib2.urlopen(request)
也可能通过add_header添加额外的header
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0')
request.add_header('Accept-Encoding','gzip, deflate')
op=urllib2.urlopen(request)
或者
opener.addheaders = [('User-agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0')]
op = opener.open(url)
多个header时用下面方法
webheader = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Host': 'www.healforce.com',
}
for key, value in webheader.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
op = opener.open(url)