python爬虫
1370 浏览 7 years, 10 months
4.3 爬取力康产品图片
版权声明: 转载请注明出处 http://www.codingsoho.com/爬取力康产品图片
#coding: utf-8
import urllib
import urllib2
import re
import settings
import os
import time
from django.http import HttpResponse
src = "[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)?ac=article&at=read&did=471"
src_home = "[http://www.healforce.com/cn/](http://www.healforce.com/cn/)"
def home(request):
# request = urllib2.Request("[http://www.baidu.com](http://www.baidu.com)")
# response = urllib2.urlopen(request)
# return HttpResponse(response.read())
values = {}
values['email'] = "hebinn@hotmail.com"
values['password'] = ""
data = urllib.urlencode(values)
url = src
request = urllib2.Request(url,data)
try:
response = urllib2.urlopen(request)
return HttpResponse(response.read())
except urllib2.HTTPError, e:
print e.code
print e.reason
return HttpResponse(e.code)
def home2(request):
html = getHtml(src)
img = getImg(html)
return HttpResponse(img)
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
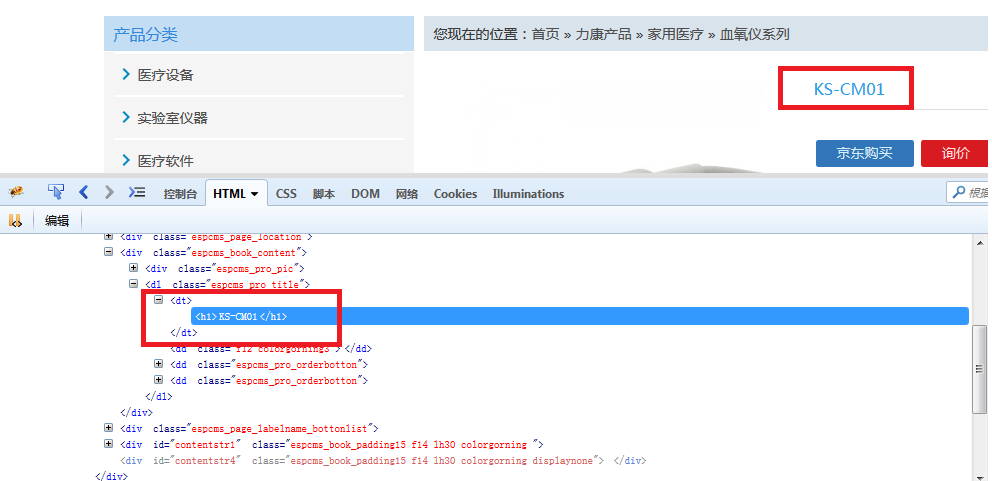
def getImg(html):
# <dt><h1>VP100鍛煎惛鏈�</h1></dt>
req = r'\<dt\>\<h1\>(.+?)\<\/h1\>\<\/dt\>'
title = re.compile(req)
titlelist = re.findall(title,html)
#filename = titlelist[0]+'-%s.jpg' % x
dir = os.path.join(settings.MEDIA_ROOT,titlelist[0])
dir_unicode = unicode(dir,'utf8')
if not os.path.exists(dir_unicode):
os.mkdir(dir_unicode)
# src="[http://www.healforce.com/cn/datacache/pic/360_300_6e7cdb990419190a1a7e7c962cc9488b.jpg](http://www.healforce.com/cn/datacache/pic/360_300_6e7cdb990419190a1a7e7c962cc9488b.jpg)" style="display: block;">
reg = r'src="(.+?\.jpg)"'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
#upfile\\2015\\12\\04\\20151204124020_996.jpg
#upfile/2015/12/04/20151204124020_996.jpg
reg = r'^(upfile.+?\.jpg)'
filename2 = re.compile(reg)
titlelist2 = re.findall(filename2,imgurl)
if len(titlelist2):
imgurl = src_home + imgurl
filename = '%s.jpg' % (x)
path = os.path.join(dir, filename)
path = unicode(path,'utf8')
if os.path.exists(path):
y = time.strftime('%Y-%m-%d-%H-%M-%S',time.localtime(time.time()))
filename = '%s.%s.jpg' % (x,y)
path = os.path.join(dir, filename)
path = unicode(path,'utf8')
try:
urllib.urlretrieve(imgurl,path)
except:
pass
x+=1
return imglist