

首先使用https://regex101.com/网站来一步步帮忙调试
域名链接
包括以下几种形式
- http://www.sina.com
- https://www.sina.com
- http://news.sina.com
- www.sina.com
- news.sina.com
- sina.com
先来一个链接的基本格式
((http(s)?:\/{2})?((www|\w+)\.)?[a-zA-Z0-9]+\.[a-zA-Z0-9]+(.cn)?
对应的说明如下
((http(s)?:\/{2})?用于匹配http://或者https://((www|\w+)\.)?一级或者二级域名名字,比如www.sina.com中的www和news.sina.com中的news,这块内容也是可有可无的,因为有时候也可以简写为sina.com[a-zA-Z0-9]+\.[a-zA-Z0-9], 对应域名,比如sina.com或者163.net(.cn)?特别处理一下,有的域名带cn结束的
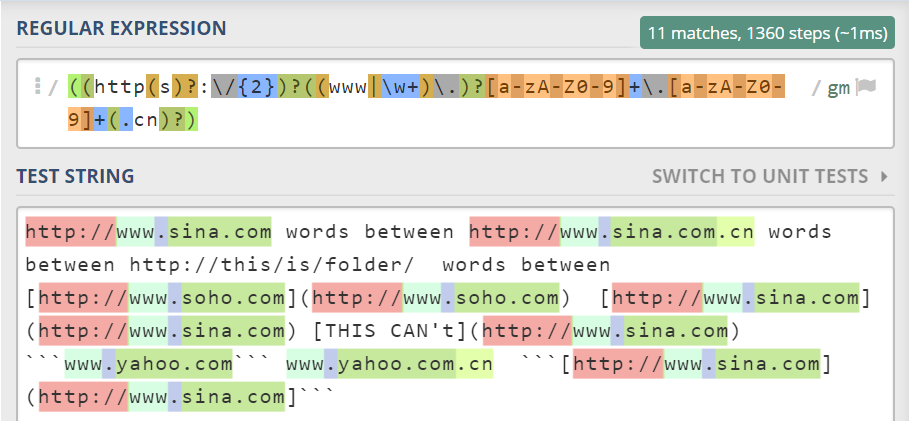
有的legacy字符串已经包含了超链接的markdown格式,这种情况我们需要从匹配里去除掉,可以用开始操作符?<!和结束操作符?!
我们不希望包含以[和(开始的以及]和)结束的超链接,以避开[http://www.sina.com] (http://www.sina.com]以及[新浪] (www.sina.com)这两种情况
格式如下
(?<![\[\(]) ....... (?![\]\)])
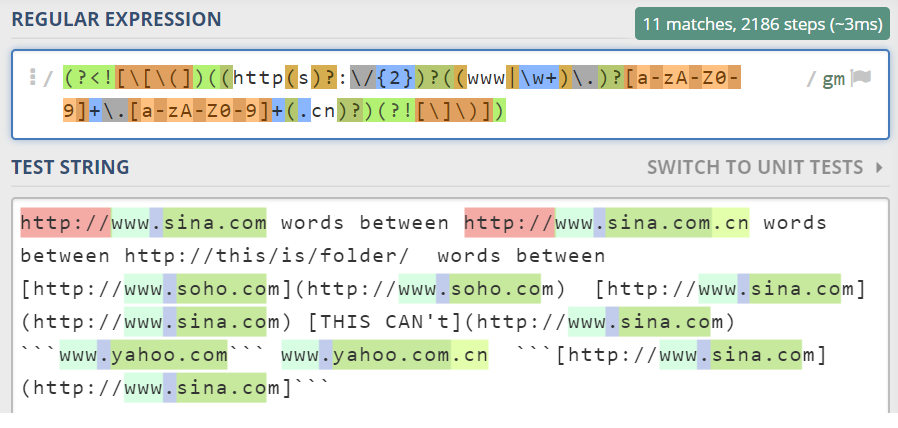
这样有一个问题, www.sina.co会被匹配到,因为http://并不是必须的,它就不匹配这个选项,从中间开始匹配了, 添加(?<![\[\(\/])来避免这个情况,让链接不能从//后面开始匹配

这样又出现了一个新的问题,ww.sina.co被匹配到了。
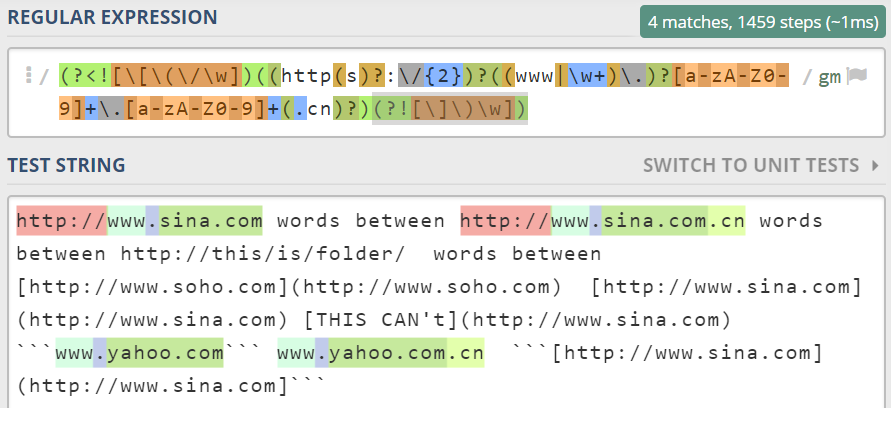
综合考虑各种情况,正常链接表达式前面不应该有字符,所以修改匹配为(?<![\[\(\/\w])....... (?![\]\)\w])
最终的匹配表达式如下
(?<![\[\(\/])((http(s)?:\/{2})?((www|\w+)\.)?[a-zA-Z0-9]+\.[a-zA-Z0-9]+(.cn)?)(?![\]\)\w])
代码如下
import re
str = "http://www.sina.com words between http://www.sina.com.cn words between http://this/is/folder/ words between [http://www.soho.com](http://www.soho.com) [http://www.sina.com](http://www.sina.com) [THIS CAN't](http://www.sina.com) www.yahoo.com www.yahoo.com.cn"
re_str = "(?<![\[\(\/\w])((http(s)?:\/{2})?((www|\w+)\.)?[a-zA-Z0-9]+\.[a-zA-Z0-9]+(.cn)?)(?![\]\)\w])"
def func(elem):
return "[{0}]({0})".format(elem.group(0))
str = re.sub(re_str, func, str)
print(str)
运行结果为
[http://www.sina.com](http://www.sina.com) words between [http://www.sina.com.cn](http://www.sina.com.cn) words between http://this/is/folder/ words between [http://www.soho.com](http://www.soho.com) [http://www.sina.com](http://www.sina.com) [THIS CAN't](http://www.sina.com) [www.yahoo.com](www.yahoo.com) [www.yahoo.com.cn](www.yahoo.com.cn)
另外一种实现方法
import re
str = "http://www.sina.com words between http://www.sina.com.cn words between http://this/is/folder/ words between [http://www.soho.com](http://www.soho.com) [http://www.sina.com](http://www.sina.com) [THIS CAN't](http://www.sina.com) www.yahoo.com www.yahoo.com.cn"
re_str = "(([^\[\(\s])?(http(s)?:\/\/)?(www.)+[a-zA-Z0-9]+\.[a-zA-Z0-9]+(.cn)?)"
rule = re.compile(re_str)
print(re.findall(rule, str))
str_list = []
for www in re.findall(rule, str):
if not www[0].strip() in str_list:
str_list.append(www[0].strip())
# str_list.sort(key=lambda elem:len(elem), reverse=True) # .cn
print(str_list)
for www in str_list:
new_format = "[{0}]({0})".format(www)
str = str.replace(new_format, www)
str = str.replace(www, new_format)
new_format2 = "([{0}]({0}))".format(www)
str = str.replace(new_format2, "({0})".format(www))
print(str)
文件路径
包括以下几种格式
- https://kubernetes.io/docs/tutorials/
- http://this/is/folder/
- http://this/is/folder/:8000
要注意一下几点
- 跟上面一样,不能处理
[]()里的链接 - 字符串中间可以支持以下特殊字符
/域名分段%中文字符.多级域名:端口- 其他支持的连接符
-+
- 我让这个链接必须以
http开始了,否则匹配表达式太复杂。所以,它基本可匹配上面的表达式,除了www.sina.com这类的. 但是从另一方面考虑,www.sina.com这种也不该匹配,这样便于处理一些非超链接的匹配格式和一些不打算转换的场景。
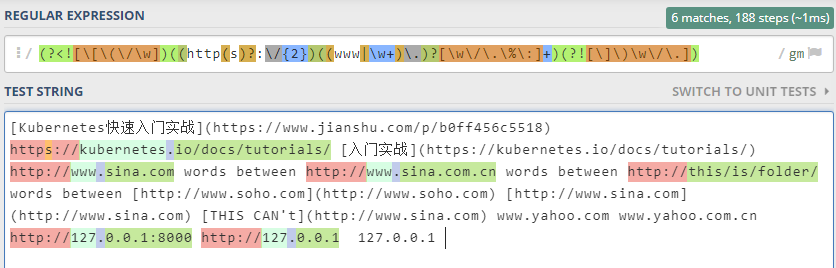
表达式如下
(?<![\[\(\/\w])((http(s)?:\/{2})((www|\w+)\.)?[\w\/\.\%\:\-\+]+)(?![\]\)\w\/\.])
保险起见,我在最后加了不允许以/.结束,这个理论上在前面已经匹配好了,可能是多余的
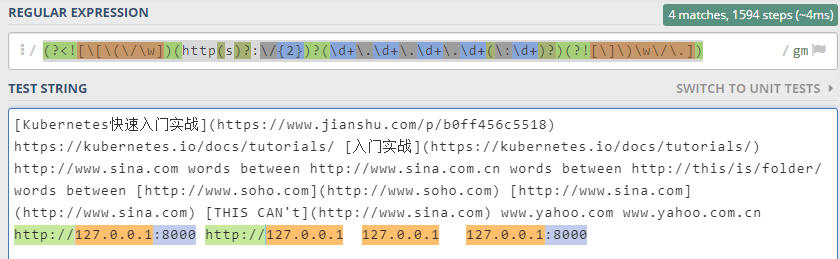
地址链接
包括以下形式
- http://127.0.0.1:8000
- 127.0.0.1:8000
- 127.0.0.1
匹配字符串如下
(?<![\[\(\/\w])(http(s)?:\/{2})?(\d+\.\d+\.\d+\.\d+(\:\d+)?)(?![\]\)\w\/\.])
工具网站
- https://regex101.com/
- https://www.regextester.com/95226

评论
留言请先登录或注册! 并在激活账号后留言!