
一.知识蒸馏
1.知识蒸馏
(1)首先,我先强调一下蒸馏学习其实本质是模型压缩!模型压缩!模型压缩!S模型有的精度高于T模型,有的低于T模型,但是可以很好地压缩网络体积。
(2)知识蒸馏是由Hiton的Distilling the Knowledge in a Neural Network 论文地址提出,并通过引入与教师网络(Teacher Network:网络结构复杂,准确率高 一般是我们的 Best_Model )相关的软目标(soft-target)作为total loss的一部分,以诱导学生网络(student network:精简、低复杂度)的训练,实现知识迁移(knowledge transfer),如下图所示(论文没图,我简单的画一下):
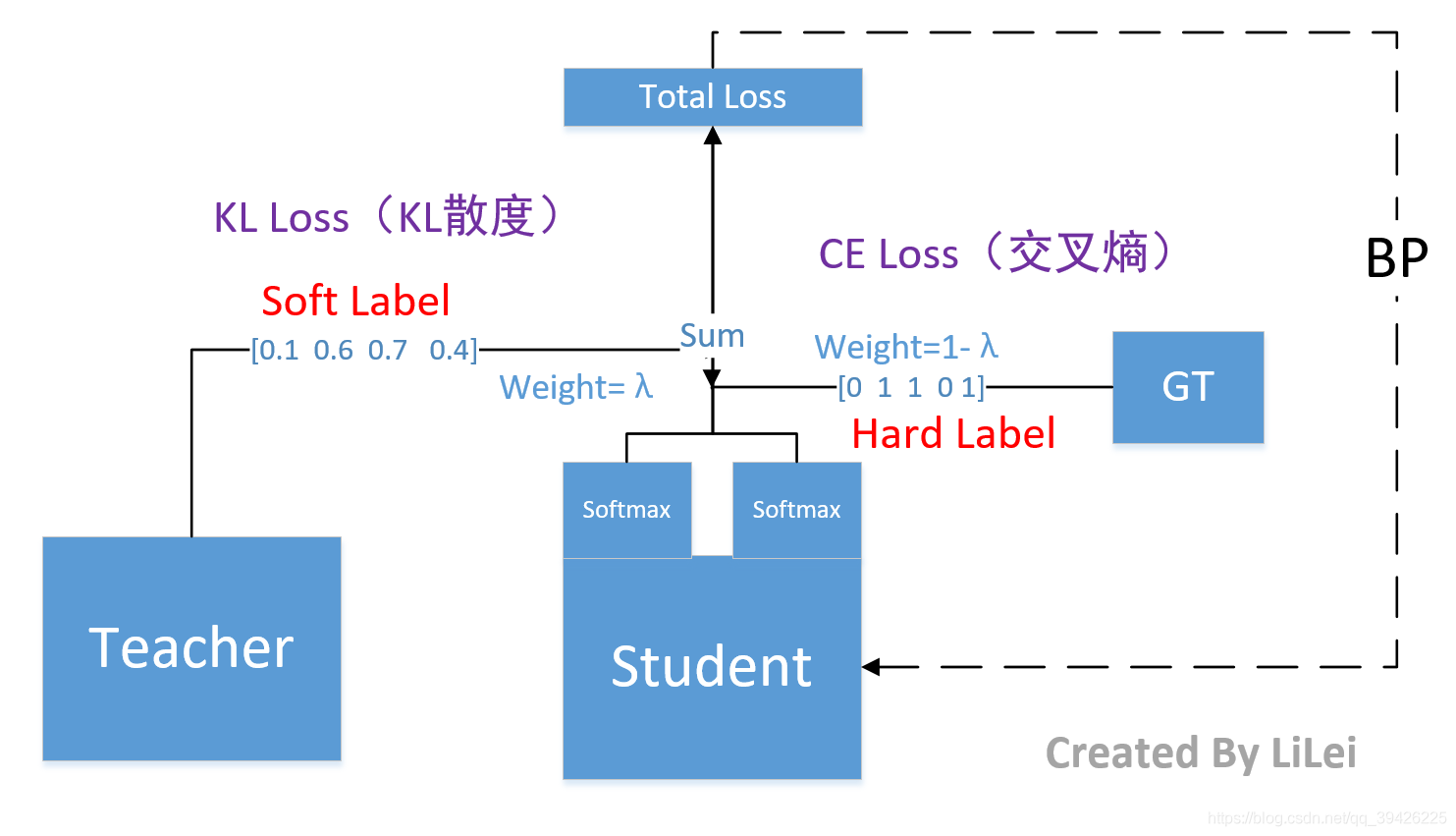
1.教师网络(Teacher)的预测输出预测值之后、再做Softmax(多分类)或Sigmoid(二分类)变换,可以获得软化的概率分布(软标签),数值介于0~1之间,取值分布较为缓和。硬标签则是样本的真实标注。
2.Total Loss设计为软标签与硬标签所对应的交叉熵的加权平均(表示为KL loss与CE loss),其中软标签交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,这对训练初期阶段是很有必要的,有助于让学生网络更轻松的鉴别简单样本,但训练后期需要适当减小软目标的比重,让真实标注帮助鉴别困难样本。另外,教师网络的推理性能通常要优于学生网络,而模型容量则无具体限制,且教师网络推理精度越高,越有利于学生网络的学习。
2.知识蒸馏 w. 联合训练
(1) 在这个部分APPRENTICE: USING KNOWLEDGE DISTILLATION TECHNIQUES TO IMPROVE LOW-PRECISION NETWORK ACCURACY,我们将ST模型一起训练。首先上面的模型是首先预训练T网络,再通过T网络来指导S网络进行学习,在这种情况下T网络的学习方式(eg:Learning Rate,Loss Function)将不会影响到S网络,这就意味着我只是将我的知识传授给你而不告诉你我是怎么学习.
(2) 下面,我们来讲讲如何进行联合训练,一些公式就不上了,我们直接上图
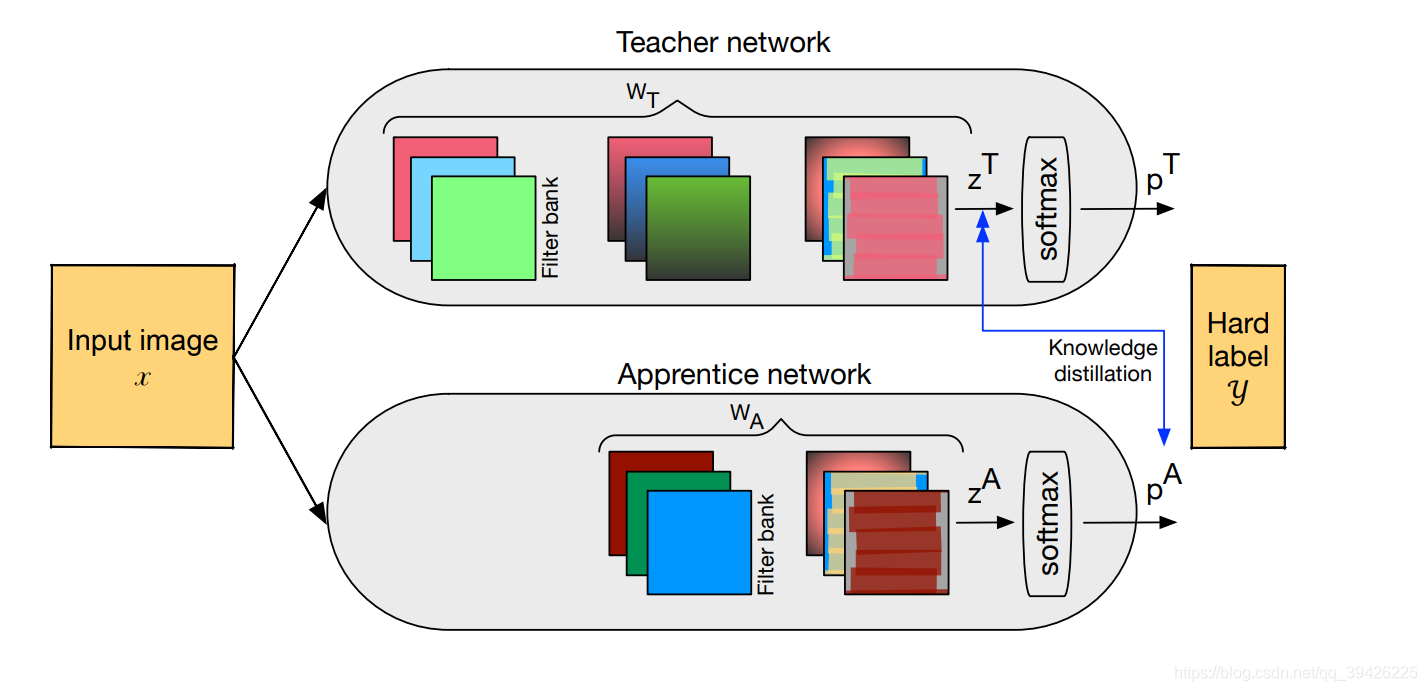
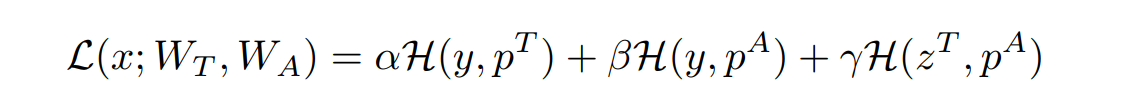
我们从Loss来看,首先这整个网络的Loss包括3个部分:
(1)T网络和真实标签之间的交叉熵
(2)S网络(即这里的A网络)和真实标签之间的交叉熵(上面的硬目标)
(3)知识蒸馏Loss:KL Loss(emmmm…一般情况下我们也可以把他称为交叉熵详见我的文章转载 KL散度、交叉熵、熵之间的区别和联系)言归正传,第三部分也就是T、S网络之间的交叉熵,也就是T网络传授给S网络暗知识(即软目标)
3.知识蒸馏 w. 多个T网络
论文地址:Efficient_Knowledge_Distillation_from_an_Ensemble_of_Teachers(这篇论文没有去申请,参考一下别人的知识)参考:知识蒸馏[https://blog.csdn.net/nature553863/article/details/80568658]
第一种算法:多个教师网络输出的soft label按加权组合,构成统一的soft label,然后指导学生网络的训练:

第二种算法:由于加权平均方式会弱化、平滑多个教师网络的预测结果,因此可以随机选择某个教师网络的soft label作为guidance:

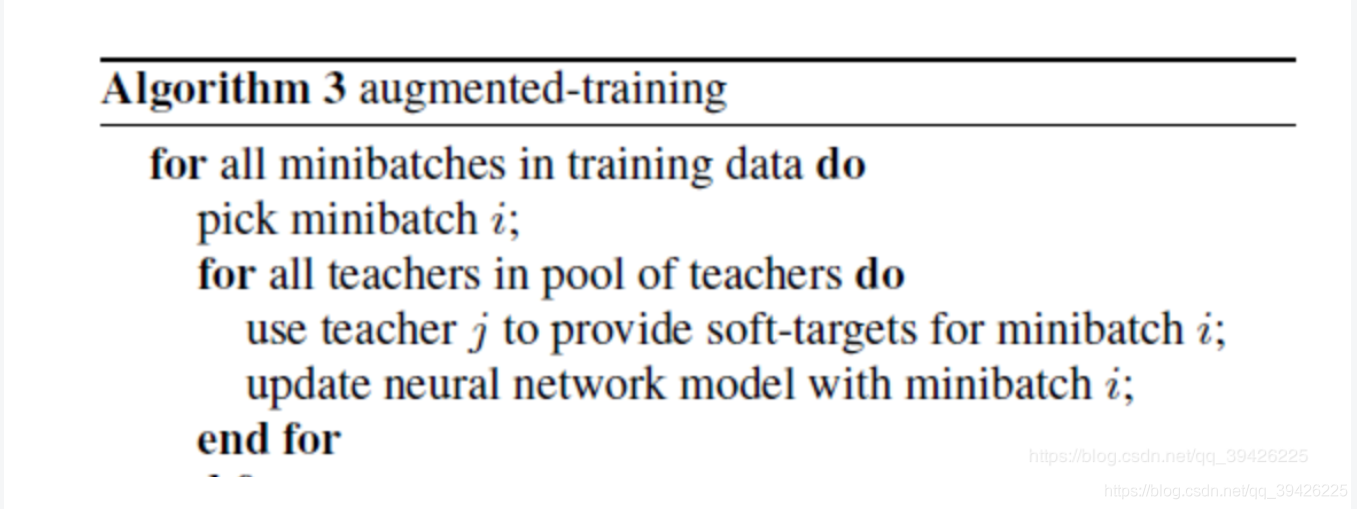
第三种算法:同样地,为避免加权平均带来的平滑效果,首先采用教师网络输出的soft label重新标注样本、增广数据、再用于模型训练,该方法能够让模型学会从更多视角观察同一样本数据的不同功能:
4.知识蒸馏 w. 特征图约束
论文地址: FITNETS: HINTS FOR THIN DEEP NETS
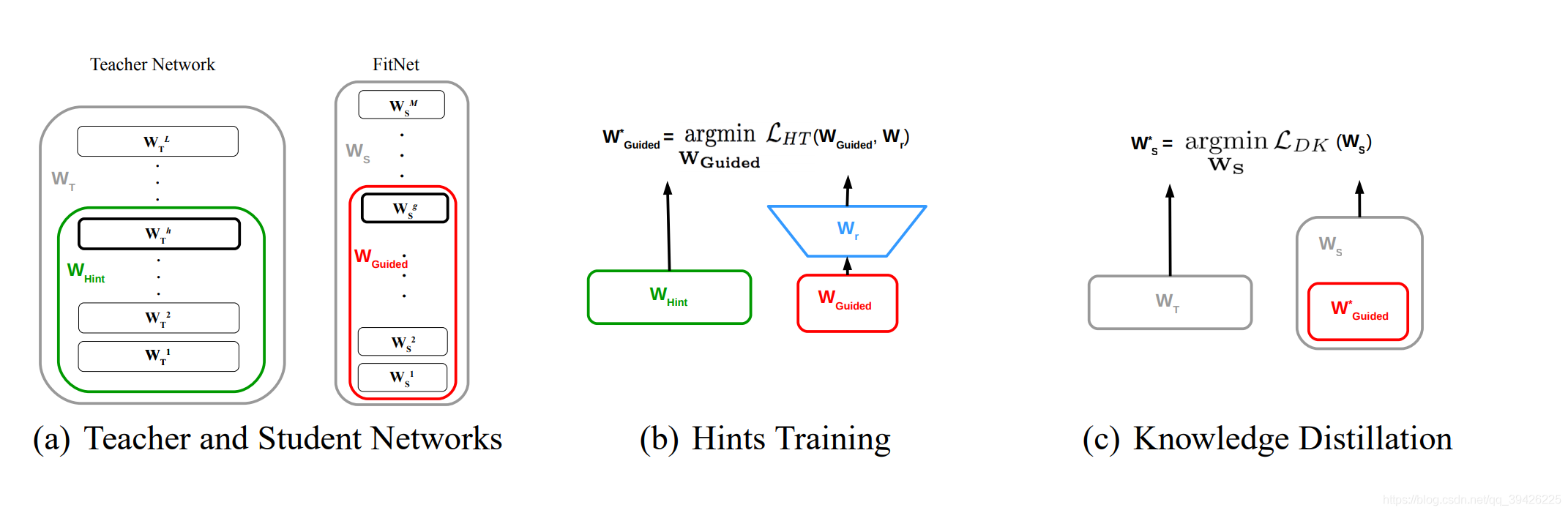
(1) Hints Training Loss
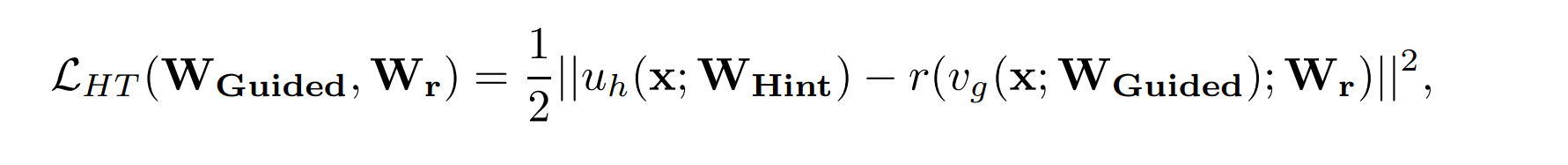
(1)首先,我们结合图片和Loss函数分析,(b)模块的目的是通过L2_Loss使T网络的Feature Map 对S网络的Feature Map的初始化来做一个指导。
(2)那么第一个问题来了,T、S网络特征图维度不同者怎么做L2约束。首先S网络的FM会通过一个图上的Wr (蓝色的部分)来放大特征图即Loss函数中的 r(),之后再通过WHint 对转换后的Wr 作L2损失进行S网络的参数初始化。
(3)第三部分就是正常的知识蒸馏,这里就不进行赘述了。
(4)这篇文章总的来说分为两个部分:1.对S网络的参数作基于T特征图的约束初始化 。 2.T网络指导S网络学习(知识蒸馏),其中在学习过程中Total Loss中Soft Target相关部分所占比重逐渐降低,从而让学生网络能够全面辨别简单样本与困难样本。
(5)最后,这里给出算法流程图,大家可以自己看一遍加深理解

二.半监督
1.什么是半监督学习
让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习(semi-supervised learning)。
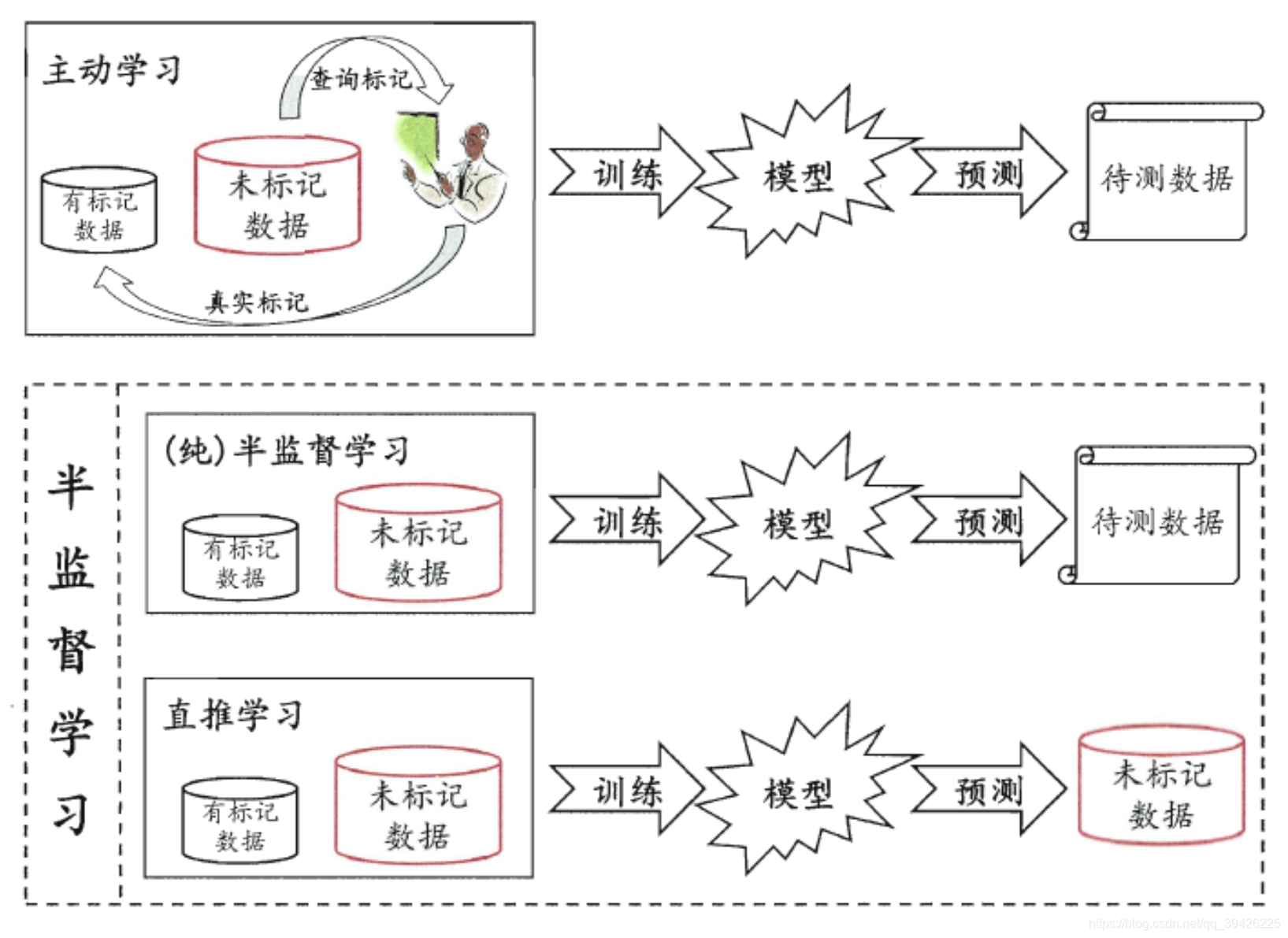
具体来说,半监督学习就是一种自训练模式,通过已有标记的数据训练模型,在通过训练的模型给无标记的数据1打上伪标签,由于预测数据集的不同又分为:(1)纯半监督学习(2)直推学习
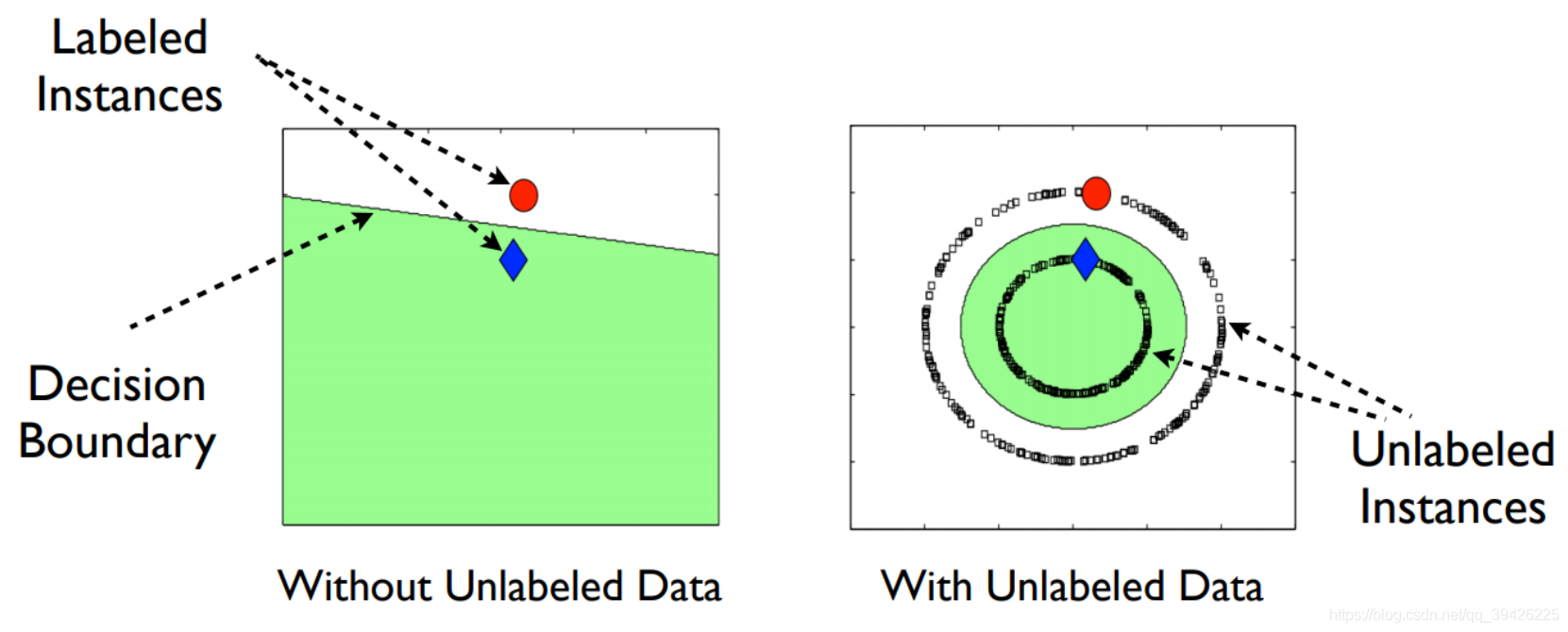
图片来源: A Tutorial on Graph-based Semi-Supervised Learning Algorithms for Speech and Spoken Language Processing
总的来说,未标记数据帮助提高模型的泛化能力,优化决策边界
三.弱监督
1.弱监督通常分为三种类型:(1)不完全监督 (2)不确切监督(3)不准确监督。
(1)不完全监督:指的是训练数据只有部分是带有标签的,同时大量数据是没有被标注过的。
(2)不确切监督:即训练样本只有粗粒度的标签,例如:只有人脸是男是女的标签,没有眼睛,鼻子…等细粒度的标签。
(3)不准确监督:即给定的标签并不总是真值。
2.通常,不完全监督包括(1)主动学习 (2)半监督学习(3)迁移学习
参考资料:
(1)https://baijiahao.baidu.com/s?id=1632614040925107215&wfr=spider&for=pc
(2)https://blog.csdn.net/nature553863/article/details/80568658
原文链接:https://blog.csdn.net/qq_39426225/article/details/105563710
