
Introduction
Images produced by generative methods have been improving lately. Most of the recent generative algorithms have made use of generative networks that are trained using a discriminator network as their adversary.
Generative Adversarial Networks (GANs) or generators, in other words, are a relatively new concept in the field of computer vision. Their aim is to generate artificial images that look like authentic images. Since they are relatively new, people have not yet fully understood the subtleties behind how and why they work.
Generators consist of an encoder and a decoder that are responsible for image generation tasks. An encoder essentially encodes the input into a vector space. The decoder then takes the activations of the encoded vector and tries to generate the most appropriate image corresponding to the input.
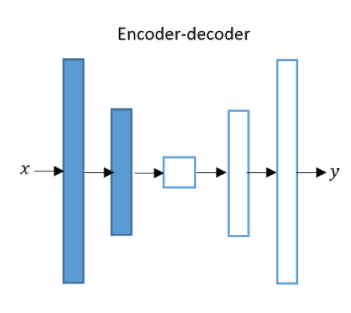
As shown in this figure, y is the output image, and x is our input. Note that here x can be an image or a randomly generated matrix depending on the task we train our generator on.
Drawbacks of the traditional generator
The generative adversarial network is the most used and the most effective technique for image generation tasks. With an increasing amount of data that these networks have access to, they have been constantly improving and pushing the states of the art. However, even though researchers are constantly pushing these networks to their limits, they also face some limitations while getting the generator to work as they want.
As you can see from the figure above, we have x as the only input to the encoder-decoder network. This means that y completely depends on x and nothing else. Say for example you wish to generate the face of an imaginary celebrity and you feed in a random vector x. The generator would then process this vector and output the corresponding face. However, you would not have fine-grain control over the facial features of this generated face. Say you wish to change the hair color. For this, you will have to experiment with different values of the vector x and these changes you make subsequently might lead to the entire face being changed.
It is evident from the point above that researchers do not have fine-grain control over the generated features of the artificial image. This arises due to the presence of a single input into the network. If we knew more about the phases of the image synthesis process and we were provided the correct pipeline to add our inputs in between the synthesis process, we would have better control over the generated features.
Background
Before StyleGan, researchers at NVIDIA had worked with ProGAN to generate high-resolution realistic images. As discussed in the pix2pix HD blog, generators tend to struggle while generating high res images. To overcome this issue, researchers began by training smaller networks and gradually upscaling them. To read more about ProGAN, you can check out this blog post and also check out the official implementation.
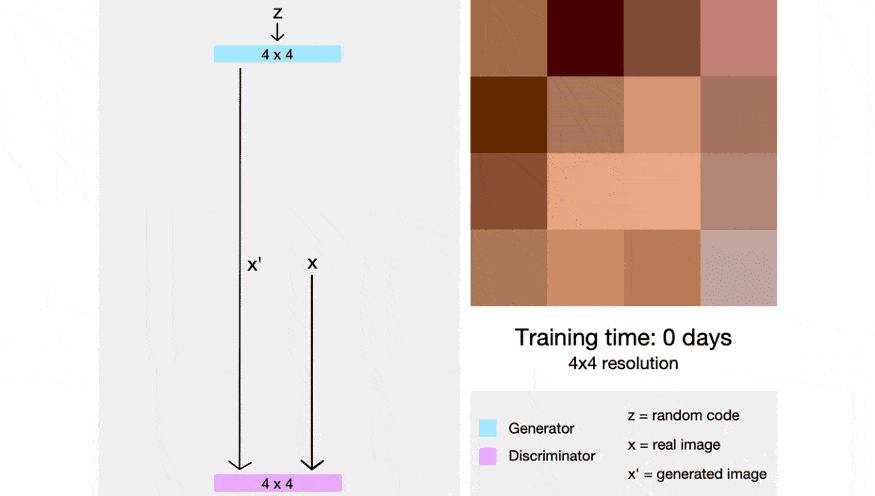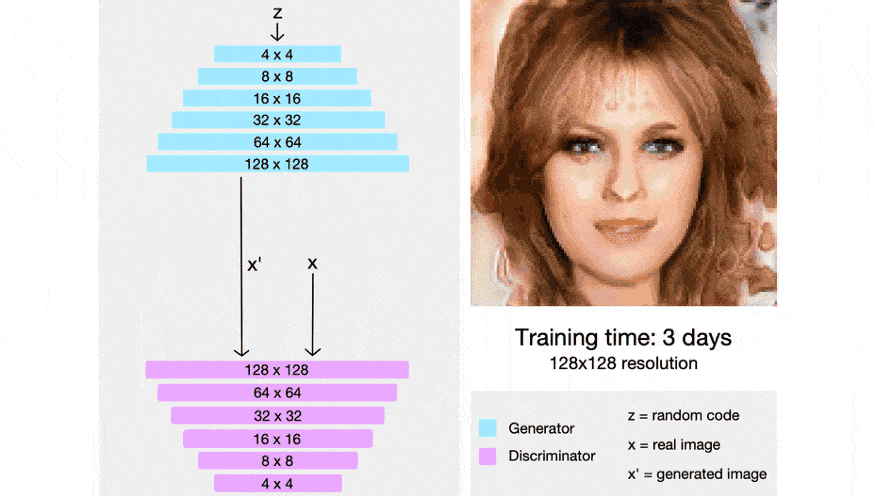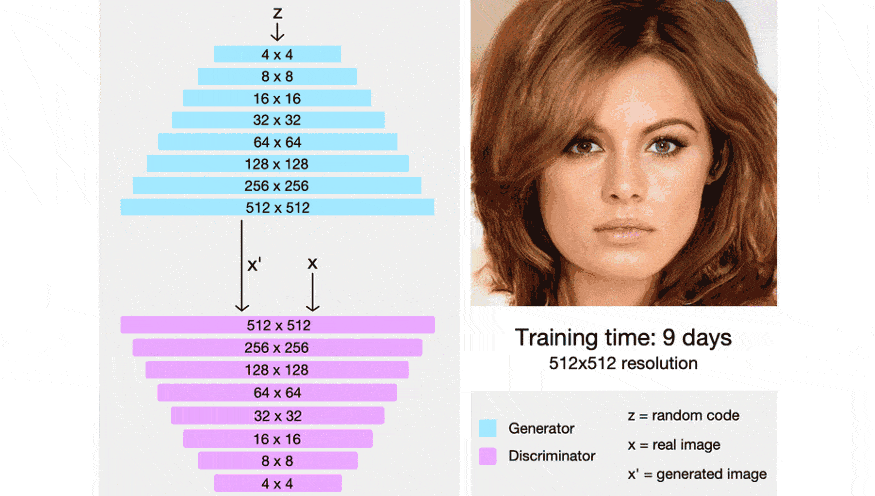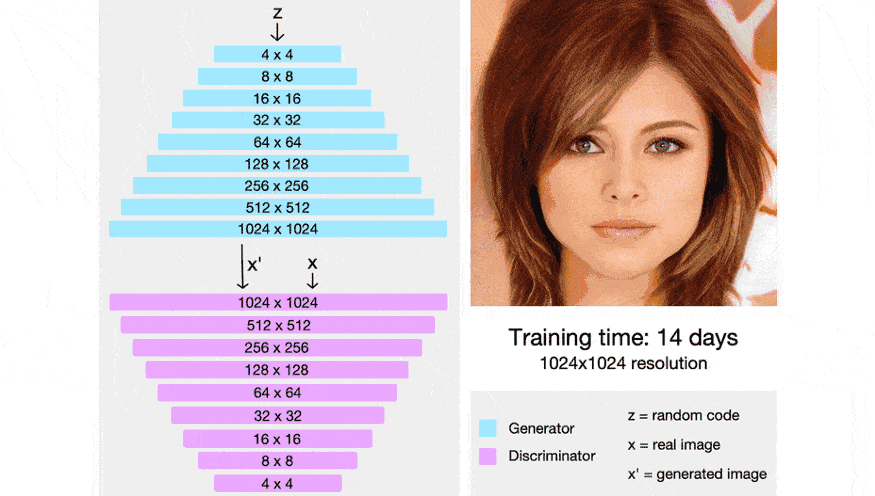
By dividing and conquering small sub-problems, researchers were able to generate highly realistic images with a good resolution.
After experimenting with this network, it was evident that different layers at varying depths have different effects on the features of the generated images. They observed that –
- Lower layers decide coarse features such as pose, face cut, and roughly the hairstyle.
- Middle layers affect finer features such as finer hairstyles, whether eyes are open or close etc.
- Ending layers decide the finest features such as eye colour, wrinkles, and other micro features.
This provided a platform to tweak layers at varying depths in order to customize the generated image.
StyleGAN
A traditional generator as discussed previously takes as input a random vector and generates the image corresponding to it.
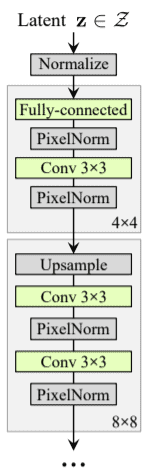
vanilla generator
Since we wish to control the finer features of the generated image, we must be enabled to provide input to intermediate layers and control the output accordingly. As a result, StyleGAN uses an enhanced version of the ProGAN with additional inputs. Furthermore, it is not fed a random vector. Rather, we use a deep non-linear mapping function to provide initial input to the generator.
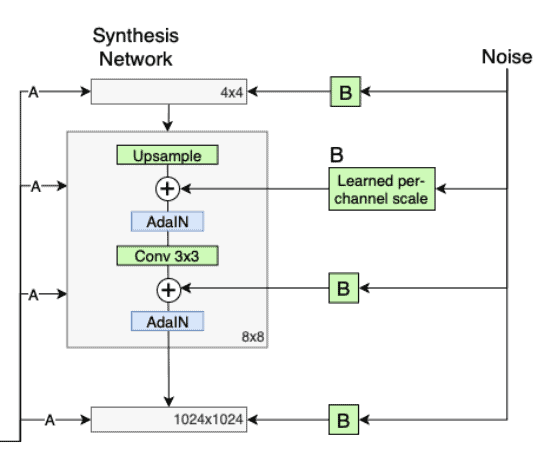
This is the block diagram of StyleGAN.
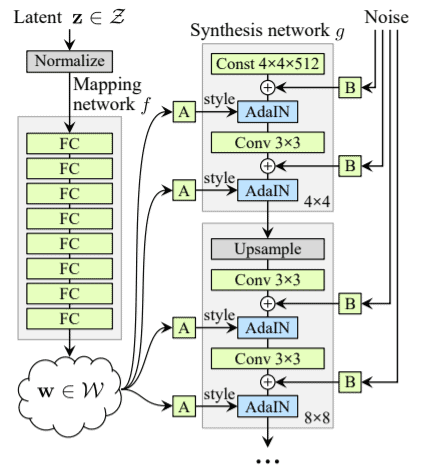
Let’s break it down into components and understand each part.
- The Fully Connected network at the beginning:
- This network consists of multiple fully connected layers
- It acts as a nonlinear mapping function and given a latent code (random vector) z in the vector space Z, the network maps it to w belonging to W.
- The dimensions of both these vector spaces are 512.
- The authors have used an 8 layer MLP.
- Style Module AdaIN
- This module transfers the information of the w vector into a usable form for the generator network.
- This is added to each resolution level.
- Before w is fed into AdaIN, it passes through A which is a learned affine transformation layer or, in other words, an MLP module. This converts w to y.
- Y = ys, yb and is responsible for controlling the ADAIN operations.
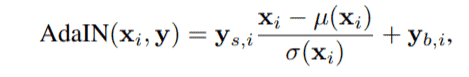
- Here, x is the input from the convolutional module after normalization.
- Noise
- Noise is fed into the generators to help them generate stochastic detail.
- These noise vectors are nothing but single channel images consisting of unrelated Gaussian noise.
The authors have used the ProGAN as the baseline and built upon it to improve images. The baseline was then slightly modified to use bilinear upsampling and downsampling to reduce the problem of checkerboard artifacts. Furthermore, the authors improved this network by adding the mapping function and AdaIN modules.
Removal of traditional input
While carrying out research, it was also observed that using a constant learned prior to training can be used as the fixed input to the first convolutional layer and it didn’t effect the quality of synthetic images. The image features controlled by AdaIN and w were capable enough of generating quality images. Hence, a constant vector was used as the input to the first conv layer.
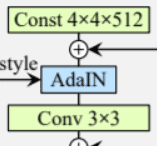
The first layer
Generating variations
There are various aspects in faces that are minute and can be considered as important entities that give identity to the face. For example, wrinkles, placement of hairs, eye colour and so on. As discussed above, the way to change these in a traditional generator is by varying input vectors slightly but this does not always work out as we expect it to.
In StyleGAN, noise added to the networks act as knobs and switches that enable us to vary the facial features. Before each layer, a scaled noise vector is added and changes in features are observed.
Using this, we can generate variations within a face by the following method.
Two sets of images were generated from their respective latent codes (sources A and B). The rest of the images were generated by copying a specified subset of styles from source B and taking the rest from source A. Copying the styles corresponding to coarse spatial resolutions brings high-level aspects such as pose, general hair style, face shape, and eyeglasses from source B, while all colors (eyes, hair, lighting) and finer facial features resemble A. If we instead copy the styles of middle resolutions from B, we inherit smaller scale facial features, hair style, eyes open/closed from B, while the pose, general face shape, and eyeglasses from A are preserved. Finally, copying the fine styles from B brings mainly the color scheme and microstructure.

Code for generating images
To generate examples, please check out this colab notebook.
Results
These are a few images that have been generated by the network. Qualitatively, the results are seen to be highly realistic and novel for varying disturbances in the noise.

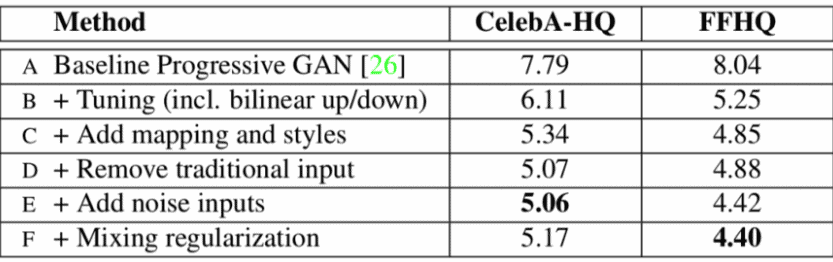
Qualitatively, the paper evaluates various configurations of the model using the Frèchet inception distance (FID) score.
The paper presents state-of-the-art results on two datasets — CelebA-HQ, which consists of images of celebrities, and a new dataset Flickr-Faces-HQ (FFHQ), which consists of images of “regular” people and is more diversified.
Continuing with StyleGAN-2
The authors observed that most images generated by StyleGan exhibit characteristic blob-shaped artifacts that resemble water droplets.

They pinpointed the problem to the AdaIN layer. Since the AdaIN layer normalizes the mean and variance of each feature map separately, it destroys any information about the magnitude of differences between the feature maps. These artifacts arise due to the generator magnifying certain unwanted activations from the input features. In images where these artifacts are missing, the picture quality is severely degraded.
To overcome these shortcomings of StyleGAN, the authors have come up with StyleGAN2 that addresses these problems.
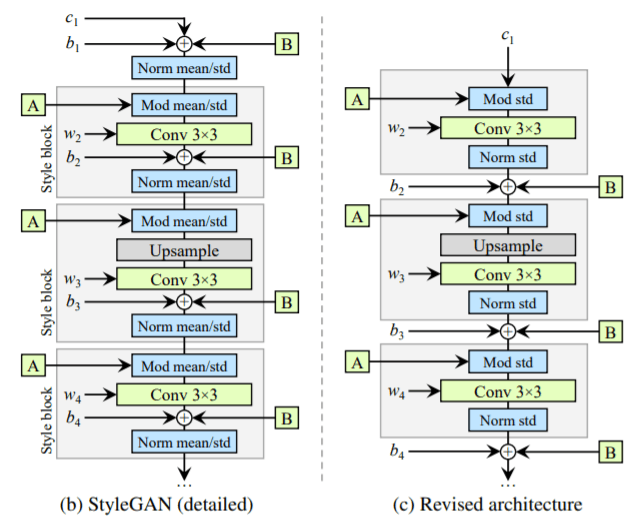
(b) is the styleGAN architecture and c) is the updated architecture. The authors found that the mean normalization operation is not required and adding/removing more of these normalization operations doesn’t improve/decrease the image quality. Furthermore, they also moved the addition of the noise module to the outside of the style box.
With this revised architecture, they found out that they can further improve the image quality by making a few more simplifications to how the weights and learned constant are input to the models. They did this by adding weight demodulation layers into the style boxes.
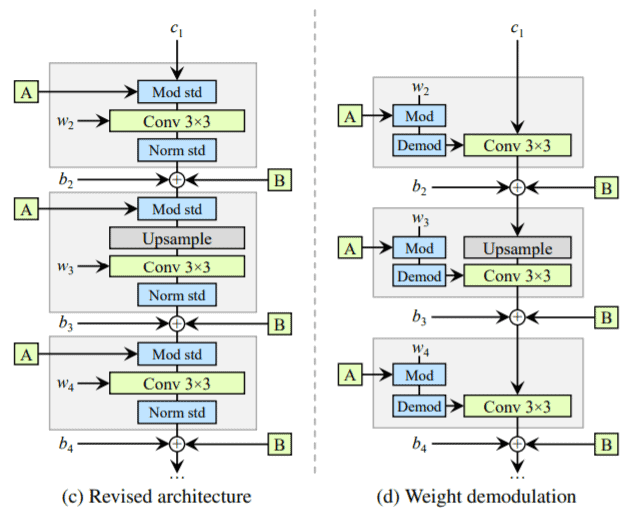
As you can see from figure (d), the normalization layers have been replaced with the weight demodulation layers. It performs the same function as the layers in figure c.
from: https://cv-tricks.com/how-to/understanding-stylegan-for-image-generation-using-deep-learning/
