
库介绍
本文主要会用到两个库requests和Beautiful Soup
requests
文档地址如下 python-requests
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
文档地址如下 BeautifulSoup
先安装好库
pip3 install requests
pip3 install beautifulsoup4
简单页面爬取
我们打算爬取yelp网站的,貌似中国的还搜不到,先爬取美国的信息
https://www.yelp.com/search?find_desc=&find_loc=San+Francisco%2C+CA&ns=1
代码如下
import requests
from bs4 import BeautifulSoup
url = 'https://www.yelp.com/search?find_desc=&find_loc=San+Francisco%2C+CA&ns=1'
yelp_r = requests.get(url)
print(yelp_r.status_code)
print(type(yelp_r))
print(yelp_r)
yelp_soup = BeautifulSoup(yelp_r.text, 'html.parser')
print(yelp_soup.prettify())
print(yelp_soup.findAll('a'))
for link in yelp_soup.findAll('a'):
print(link)
首先,通过requests.get获取网页信息,返回的status_code值为200表示正常返回。
读到页面内容后,通过BeautifulSoup转化为bs4格式,经过prettify清洗,接着可以执行相关的搜索操作
打印结果如下,是页面上的所有超链接
<a href="/atlanta">Atlanta</a>
<a href="/austin">Austin</a>
<a href="/boston">Boston</a>
<a href="/chicago">Chicago</a>
<a href="/dallas">Dallas</a>
<a href="/denver">Denver</a>
<a href="/detroit">Detroit</a>
<a href="/honolulu">Honolulu</a>
<a href="/houston">Houston</a>
<a href="/la">Los Angeles</a>
<a href="/miami">Miami</a>
<a href="/minneapolis">Minneapolis</a>
<a href="/nyc">New York</a>
<a href="/philadelphia">Philadelphia</a>
<a href="/portland">Portland</a>
<a href="/sacramento">Sacramento</a>
<a href="/san-diego">San Diego</a>
<a href="/sf">San Francisco</a>
<a href="/san-jose">San Jose</a>
<a href="/seattle">Seattle</a>
<a href="/dc">Washington, DC</a>
<a href="/locations">More Cities</a>
<a href="https://yelp.com/about">About</a>
<a href="https://officialblog.yelp.com/">Blog</a>
<a href="https://www.yelp-support.com/?l=en_US">Support</a>
<a href="/static?p=tos">Terms</a>
<a href="http://www.databyacxiom.com" rel="nofollow" target="_blank">Some Data By Acxiom</a>
题外话,指向上述语句时,在print时报错
UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 61522: illegal multibyte s
添加下面语句可解决
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
参考链接 http://www.cnblogs.com/feng18/p/5646925.html
抓取搜索结果名字
上面的代码中,地址是固定的,这样如果我们想换个城市来搜索的话,代码就要重写了
添加下面代码,可以灵活的搜索不同城市,同时增加了页面定位参数
base_url = 'https://www.yelp.com/search?find_desc=&find_loc='
loc = 'San+Francisco%2C+CA&ns=1'
page = 10
url = base_url + loc + "&start=" + str(page)
在前面的代码中,我们找出了所有的a,但并不是都是我们想要的。
我们先尝试把各个目标对象找出来,从下面图中可以看出来,每个搜索结果对应一个li,并且它的class固定为regular-search-result
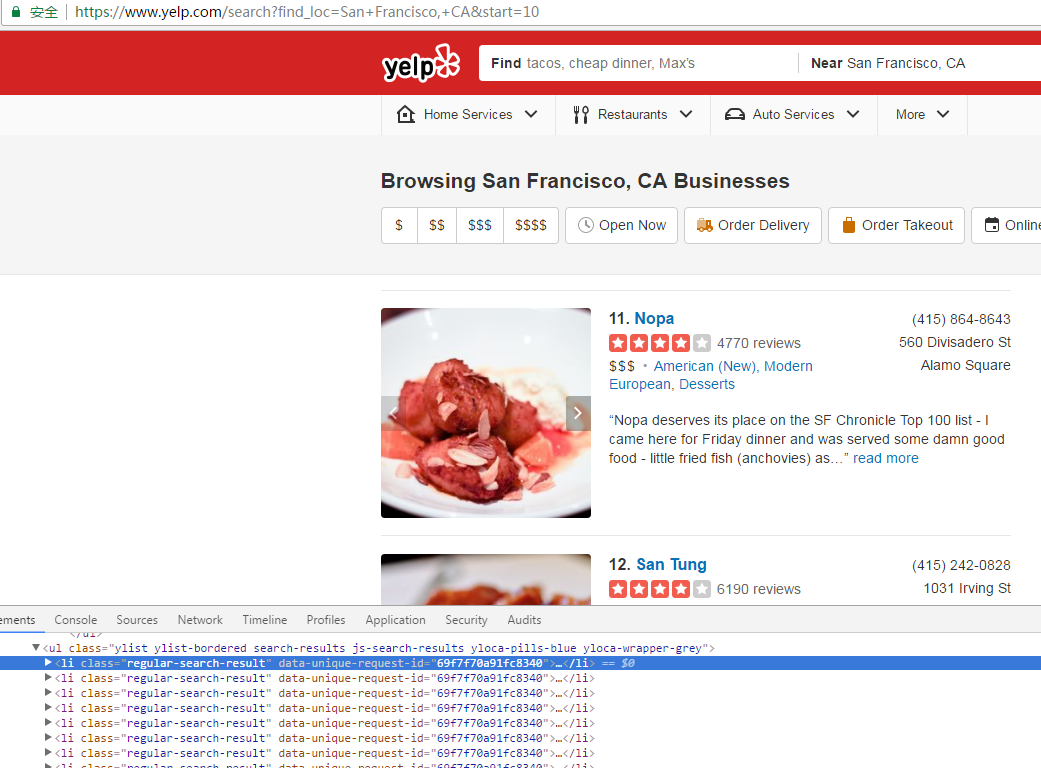
print(yelp_soup.findAll('li', {'class':"regular-search-result"}))
这段代码可以搜索出所有的包含该class的结果,通过findAll函数进行搜索,第二个参数指名了class信息
同样的方法,我们继续搜索a,这次具体到搜索结果上标题的这个a,图片如下,它的class为biz-name
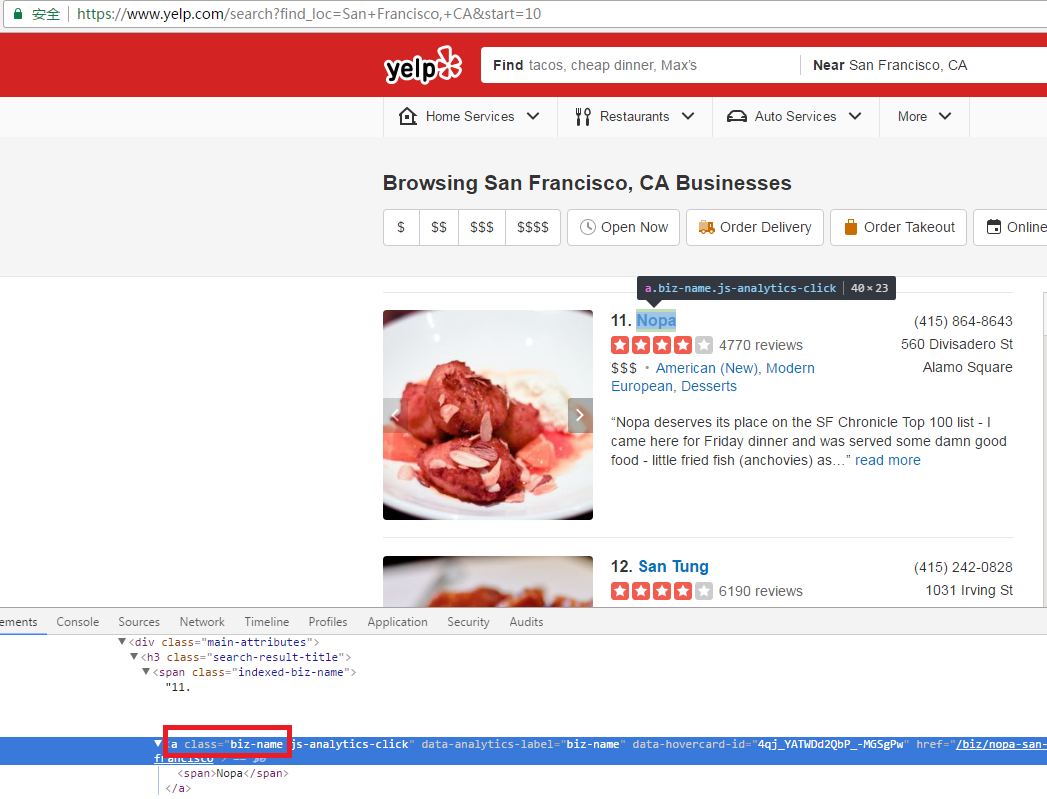
添加下面代码
print(yelp_soup.findAll('a', {'class':"biz-name"}))
for name in yelp_soup.findAll('a', {'class':"biz-name"}):
print(name.text)
搜索结果如下
[<a class="biz-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="4qj_YATWDd2QbP_-MGSgPw" href="/biz/nopa-san-francisco"><span>Nopa</span></a>, <a class="b
iz-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="UM8uywr0zv0EnxZh7DB9nA" href="/biz/san-tung-san-francisco-2"><span>San Tung</span></a>, <a class="biz
-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="FTdnh0HddvyTGr0VWL3-Kg" href="/biz/el-farolito-san-francisco-2"><span>El Farolito</span></a>, <a class=
"biz-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="oaMm3f-y9Kyu9HWrc7VnkQ" href="/biz/b-patisserie-san-francisco-2"><span>B Patisserie</span></a>, <a
class="biz-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="ITD_boyY2MhFkJYOQqvu6w" href="/biz/zazie-san-francisco"><span>Zazie</span></a>, <a class="biz
-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="LlyyZ07DjdAARuhZSDnUAQ" href="/biz/saigon-sandwich-san-francisco"><span>Saigon Sandwich</span></a>, <a
class="biz-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="N40oyUcauyEPNpsf85jxSA" href="/biz/fog-harbor-fish-house-san-francisco-2"><span>Fog Harbor Fi
sh House</span></a>, <a class="biz-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="xaapg5_zT7_X_qYsxN4ghw" href="/biz/foreign-cinema-san-francisco"><spa
n>Foreign Cinema</span></a>, <a class="biz-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="c2l-3SHXq0dJGwRrBAxPww" href="/biz/golden-boy-pizza-san-franc
isco"><span>Golden Boy Pizza</span></a>, <a class="biz-name js-analytics-click" data-analytics-label="biz-name" data-hovercard-id="JbQg5HSQzcRhXdtijx0GuA" href="/biz/golden-gate-ba
kery-san-francisco"><span>Golden Gate Bakery</span></a>]
Nopa
San Tung
El Farolito
B Patisserie
Zazie
Saigon Sandwich
Fog Harbor Fish House
Foreign Cinema
Golden Boy Pizza
Golden Gate Bakery
抓取搜索结果主要信息并存储
接下来我们取出搜索结果的地址信息等
从下面代码Inspection可以看出来,每个搜索结果对应一个div,我们可以先找出这个div,然后再在里面找出对应的address,这样比较定位准确
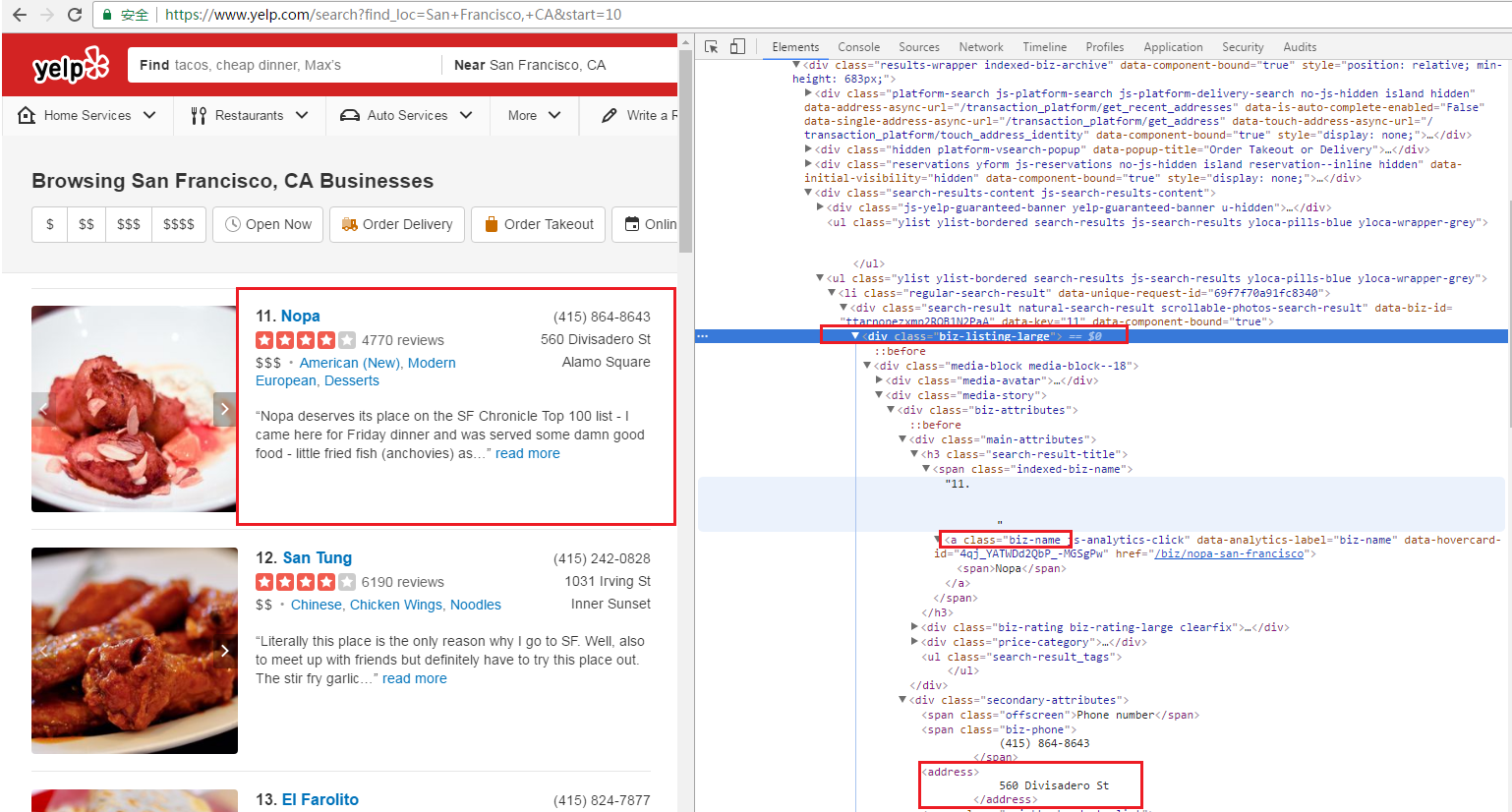
首先可以用这种方法先搜索前面的名称,代码如下
businesses = yelp_soup.findAll('div', {'class':"biz-listing-large"})
for biz in businesses:
title = biz.findAll('a', {'class':"biz-name"})[0].text
print(title)
首先搜索出所有的class为biz-listing-large的div,然后轮询结果列表,取出每个里面的class为biz-name的a
同样的方法,取出地址,代码如下
businesses = yelp_soup.findAll('div', {'class':"biz-listing-large"})
for biz in businesses:
title = biz.findAll('a', {'class':"biz-name"})[0].text
print(title)
address = biz.findAll('address')[0].text
print(address)
打印结果
Nopa
560 Divisadero St
San Tung
1031 Irving St
El Farolito
2779 Mission St
......
同样的方法抓取电话信息
phone = biz.findAll('span', {'class':"biz-phone"})[0].text
print(phone)
现在,我们把搜索到的信息存储到文件里
代码如下
file_path = 'yelp-{loc}.txt'.format(loc=loc)
with open(file_path, "a") as textfile:
businesses = yelp_soup.findAll('div', {'class':"biz-listing-large"})
for biz in businesses:
title = biz.findAll('a', {'class':"biz-name"})[0].text
print(title)
address = biz.findAll('address')[0].text
print(address)
print('\n')
phone = biz.findAll('span', {'class':"biz-phone"})[0].text
print(phone)
page_line = "{title}\n{address}\n{phone}\n\n".format(
title=title,
address=address,
phone=phone,
)
textfile.write(page_line)
这个是比较普通的文件存储代码,首先根据location名字存储不同的文件名,然后打开文件,并将前面的内容写进去
这儿用with打开文件,它会在完成之后自动关闭文件
翻页和结果优化
添加翻页功能支持
import requests
from bs4 import BeautifulSoup
base_url = 'https://www.yelp.com/search?find_desc=&find_loc='
loc = 'San+Francisco%2C+CA&ns=1'
current_page = 0
while current_page < 201:
url = base_url + loc + "&start=" + str(current_page)
yelp_r = requests.get(url)
yelp_soup = BeautifulSoup(yelp_r.text, 'html.parser')
file_path = 'yelp-{loc}.txt'.format(loc=loc)
with open(file_path, "a") as textfile:
businesses = yelp_soup.findAll('div', {'class':"biz-listing-large"})
for biz in businesses:
title = biz.findAll('a', {'class':"biz-name"})[0].text
print(title)
try:
address = biz.findAll('address')[0].text
except:
address = None
print(address)
print('\n')
try:
phone = biz.findAll('span', {'class':"biz-phone"})[0].text
except:
phone = None
print(phone)
page_line = "{title}\n{address}\n{phone}\n\n".format(
title=title,
address=address,
phone=phone,
)
textfile.write(page_line)
current_page += 10
对于address和phone的获取使用了try语句,以免碰到结果为空的情况
接下来优化地址的显示,通过address = biz.findAll('address')[0].contents可以查看地址的显示列表,结果如下
['\n 501 Twin Peaks Blvd\n ']
有的结果里会包含<br>
通过下面代码进行优化
try:
address = biz.findAll('address')[0].contents
except:
address = None
print(address)
if address:
for item in address:
if "br" in str(item):
print(item.getText())
else:
print(item.strip(" \n\t\r"))
这个只是当前的一个比较合理的方法,并不一定是最优的。
可以通过strip(" \n\t\r")去掉空行
该段代码进行存储时是放进了txt文件,一些常用的存放文件是csv,我们也可以创建对象,把它们存放到数据库
