
原文:经典GAN不得不读:StyleGAN - 知乎 (zhihu.com)
A Style-Based Generator Architecture for Generative Adversarial Networks
- CVPR 2020之117篇GAN论文分类汇总清单mp.weixin.qq.com/s?__biz=MzU5MTgzNzE0MA==&mid=100002834&idx=1&sn=7d1c740509ba6b65f630f6db6bd51d7b&chksm=7e29aea9495e27bfa746902298298c921320c3cb13a0619824528c3d1803f533779b7a93a242#rd
- 等你着陆!【GAN生成对抗网络】知识星球!mp.weixin.qq.com/s?__biz=MzU5MTgzNzE0MA==&mid=100007403&idx=1&sn=dca20015ad5038e0da4fbfa8a1a961c7&chksm=7e29bf50495e364687f9161ea0ab47fb1f9367ed93cc3b7a8875a0bea6cb29058581e9bddbec#rd
1. 摘要
- StyleGAN受风格迁移style transfer启发而设计了一种新的生成器网络结构。新的网络结构可以通过无监督式的自动学习对图像的高层语义属性做一定解耦分离,例如人脸图像的姿势和身份、所生成图像的随机变化如雀斑和头发等。也可以做到一定程度上的控制合成。
- 为了量化插值质量和解纠缠度,还提出了两种计算方法。 最后,还介绍一个新的、高度多样化和高质量的人脸数据集。
2. 背景
- GAN所生成的图像在分辨率和质量上都得到了飞速发展,但在此之前很多研究工作仍然把生成器当作黑箱子,也就是缺乏对生成器进行图像生成过程的理解,例如图像多样性中的随机特征是如何控制的,潜在空间的性质也是知之甚少。
- 受风格迁移启发,StyleGAN重新设计了生成器网络结构,并试图来控制图像生成过程:生成器从学习到的常量输入开始,基于潜码调整每个卷积层的图像“风格”,从而直接控制图像特征;另外,结合直接注入网络的噪声,可以更改所生成图像中的随机属性(例如雀斑、头发)。StyleGAN可以一定程度上实现无监督式地属性分离,进行一些风格混合或插值的操作。
3. 基于风格驱动的生成器
- 在以往,潜码仅喂入生成器的输入层。而StyleGAN是设计了一个非线性映射网络f对输入的潜在空间Z中的潜码z进行加工转换:Z→W(w∈W)。为简单起见,将两个空间的维数都设置为512,并且使用8层MLP实现映射f。
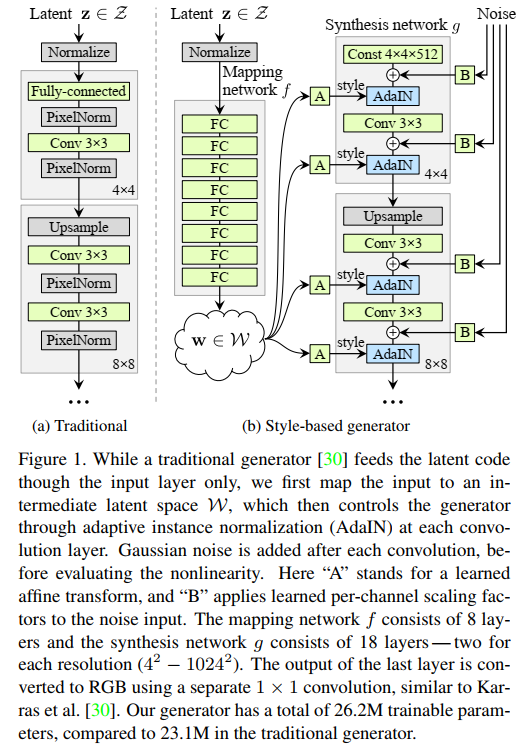
- 非线性映射也就是学习到的仿射变换将w定制化为风格y =(ys,yb),它们在接下来的生成网络g中每个卷积层之后被用于控制自适应实例归一化(AdaIN)。AdaIN运算定义为如下式所示。其中,每个特征图xi分别归一化,然后使用y中对应的标量。因此,y的维数是该层特征图的两倍。与风格迁移不同,StyleGAN是从向量w而不是风格图像计算而来。
- 最后,通过对生成器引入噪声输入,提供了一种生成随机(多样性)细节的方法。噪声输入是由不相关的高斯噪声组成的单通道数据,它们被馈送到生成网络的每一层。
4. StyleGAN的特点
4.1 风格混合
- 为了进一步明确风格控制,StyleGAN采用混合正则化手段,即在训练过程中使用两个随机潜码而不仅仅是一个。在生成图像时,只需在生成成网络中随机选择一个位置,把一个潜码切换到另一个潜码(称为风格混合)即可。具体来说,通过映射网络运行两个潜码z1和z2,得到相应的w1和w2控制风格,然后w1被用在网络所被选择的位置点之前,w2在该位置点之后使用。

- 图3(论文中)展示了一些通过以在不同网络层的空间尺度上混合两个潜码而生成的图像例子。可以看到,不同层次的风格可以控制一些有语义的高级图像属性。
4.2 随机变化
- 人像中有许多方面的细节可被认为是随机变化着的,例如头发、雀斑或皮肤毛孔等细节。实际上,只要这些细节遵循着某种我们认为正确的“分布”,那么就是合理的。
- 传统的生成器一般有着唯一输入,而我们期望可以生成在图像空间上有一些随机的(细节)变化。这并不简单,以往方法总很难实现。StyleGAN的架构通过在每次卷积后添加噪声来解决这些问题。

- 图4显示了使用我们的生成器以不同的噪声实现方式生成的相同基础图像的随机实现方式。我们可以看到,噪声仅影响随机方面,而整体构成和高级方面(如身份)保持不变。

- 图5进一步说明了将随机变化应用于不同层子集的效果。(a)噪声应用于所有层;(b)无噪音;(c)噪音仅精细层(64– 1024);(d)仅在粗糙层中产生噪音(4– 32)。 可以看到,粗糙的噪音会导致头发大量卷曲,并出现较大的背景特征,而细腻的噪音散发出更细的卷发、更细腻的背景细节和皮肤毛孔。
4.3 分离整体的风格效应与局部的随机变化
- 风格影响的是整体(改变姿势、身份等),噪音影响无关紧要的随机变化(头发、胡须等)。
5. 解纠缠研究
- 解纠缠(disentanglement)有多种定义,目标都是由线性子空间组成的潜在空间,每个子空间控制一个变化因子。
- 图6展示了具有两个变化因素(例如男性气质和头发长度)的纠缠例子。 (a)训练集中这些因素的某些组合(例如长发男性)是不存在的;(b)这迫使从Z到图像特征的映射变得弯曲,因为要防止采样去生成训练集中不存在的因素组合;(c)而添加了新映射网络即从Z到W的映射能够消除大部分这些纠缠。StyleGAN的作者们提供了两种量化解缠结的方法。
5.1 感知路径长度
- 潜在空间向量的插值可能会在图像中产生令人意想不到的非线性变化。例如,插值端点中不存在的图像元素可能会出现在线性插值路径的中间,这就表明潜在空间有纠缠现象、因子未能正确分离。为了量化这种现象,可以计算在潜在空间中执行插值时图像经历的变化程度。直观地,纠缠程度较小的潜在空间应比纠缠程度较高的潜在空间在感知上过渡更自然平滑。
- 作为度量标准的基础,使用基于感知的成对图像距离,该距离是通过计算两个VGG16的嵌入特征之间的距离得出。如果将潜在空间插值路径细分为线性段,则可以将这些路径段的距离之和定义为总感知长度。感知路径长度的自然定义是无限细分下所有路径段的极限,但实际上使用较小的细分
来进行近似计算。
- 因此,在所有可能的端点上,潜在空间Z中的平均感知路径长度如下所示,其中t〜U(0; 1),G是生成器,而d(·;·)评估结果图像之间的感知距离,在这里表示球面插值,这是在归一化输入潜伏中进行插值的最合适方法空间。在人脸数据上,为专注于面部特征而不是背景,将生成的图像裁剪为仅包含脸部。指标d是二次方,除以
的二次方。
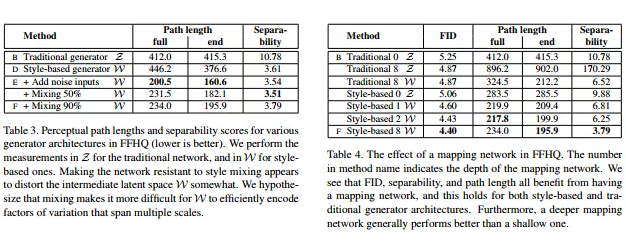
- 计算W中的平均感知路径长度以类似的方式执行,唯一的区别是插值发生在W空间。因为W中的向量未归一化,使用线性插值(lerp)。表3表明,该全路径(细分距离段)长度实际上对带有噪声输入的StyleGAN来说更短,这表明W比Z更线性可分一些。如果W确实是Z的一个更解纠缠、“展平”的映射(Z可能包含训练数据分布不存在的因子,生成器会生成不合理的数据),因此可预期如果将测度限制为路径终点,即
,
会相对变小,而
不受影响。如表3所示,实验也证实了这一点。
- 表4显示了映射网络如何影响路径长度:无论是传统的和基于风格的生成器,映射网络都能让它们变得更好。
5.2 线性可分性
- 如果潜在空间的“纠缠”解开,则应该有可能找到对应于各个变化因子的方向向量。StyleGAN的作者们也提出了另一个度量标准,通过测量在潜在空间的点可由线性超平面分为两个不同集合的程度来进行量化,以便每个集合都对应于图像的某种二分类属性。
- 为得到有标签的生成图像,针对许多二分类类别训练了辅助分类网络,例如男性和女性面孔。其中,分类器与判别器具有相同的架构,并使用CELEBA-HQ数据集进行训练,该数据集保留了原始CelebA数据集中的40个类别属性。为了测量一个类别属性的可分离性,在z〜P(z)上采样通过GAN生成200,000张图像,并用辅助分类网络对其进行分类。然后,根据分类器的置信度对样本进行排序,并去除最低置信度的一半,从而产生100,000个带标记的潜在空间向量。
- 对于每个属性,使用线性SVM来基于潜在空间点(传统的z和基于样式的w)来预测标签。然后,计算条件熵H(Y|X),其中X是SVM预测的类,Y是预训练分类器确定的类;它告诉我们确定样本的真实类别还需要多少其他信息,较低的值表明对应的变化因子具有一致的潜在空间方向。将最终的可分离性得分计算为
,其中i列举了40个属性。与 inception scor相似,幂运算将值从对数域扩展到线性域,以便于比较。表3和表4表明W始终比Z具有更好的可分离性,即表明纠缠程度较小。
6. 总结
- StyleGAN的设计相较于传统GAN的生成器结构更胜一筹,尤其是对高级属性和随机变化(的多样性)方面的分离、中间潜在空间的线性研究增进了我们对GAN的理解和可控性生成。
本文首发公众号【机器学习与生成对抗网络】,加入最多大佬的交流群共同进步!
---
本文首发公众号【机器学习与生成对抗网络】
- GAN整整6年了!是时候要来捋捋了!
- 盘点GAN在目标检测中的应用
- 数百篇GAN论文已下载好!搭配一份生成对抗网络最新综述!
- 新手指南综述 | GAN模型太多,不知道选哪儿个?
- 人脸图像GAN,今如何?(附多篇论文下载)
- 人脸生成新SOTA?
- 语义金字塔式-图像生成:一种使用分类模型特征的方法
- 拆解组新的GAN:解耦表征MixNMatch
- 2021年1月50篇GAN/对抗论文汇总
- 2020年12月100篇GAN/对抗论文汇总
- 2020年11月80篇GAN/对抗论文汇总
- CVPR 2020 | StarGAN第2版:多域多样性图像生成
- CVPR 2020 | GAN中的反射/反光、阴影
- CVPR 2020 | 几篇GAN语义生成论文
- CVPR 2020 | 10篇改进GAN的论文(网络、训练、正则等)
- CVPR 2020 | 11篇GAN图像转换img2img 的论文
- CVPR2020之MSG-GAN:简单有效的SOTA?
- CVPR2020之姿势变换GAN
- CVPR2020之多码先验GAN:预训练好的模型怎么使用?
- 两幅图像!这样能训练好 GAN 做图像转换吗?
- ECCV 2020 的对抗相关论文(对抗生成、对抗攻击)
- 经典GAN不得不读:StyleGAN
- 最新最全20篇!基于 StyleGAN 改进或应用相关论文
- 2020年10月80篇GAN/对抗论文汇总
- 2020年9月70篇GAN/对抗论文汇总
- 2020年8月60篇GAN/对抗论文汇总
- 2020年7月90篇GAN/对抗论文汇总
- 2020年6月100篇GAN/对抗论文汇总
- 2020年5月60篇GAN论文汇总
- 最新下载!2020年4月份70多篇GAN论文!
- 最新下载!一览2020年3月至今90多篇GAN论文!
- 最新下载!一览2020年2月50多篇GAN论文!
- 一览!2020年1月份的GANs论文!
- 2019年12月份的GANs论文一览
- 这么多!11月份来的这些GAN论文都在解决什么方向的问题?
部分应用介绍:
- 脸部转正!GAN能否让侧颜杀手、小猪佩奇真容无处遁形?
- 【无中生有的AI】关于deepfake的入门级梳理
- 容颜渐失!GAN来预测?
- 异常检测,GAN如何gan?
- 虚拟换衣!这几篇最新论文不来GAN GAN?
- 脸部妆容迁移!速览几篇用GAN来做的论文
- 有点夸张、有点扭曲!速览GAN如何夸张漫画化人脸!
- 见微知细之超分辨率GAN!附70多篇论文下载!
- 天降斯雨,于我却无!GAN用于去雨如何?
- 结合GAN的零次学习(zero-shot learning)
- 强数据所难!SSL(半监督学习)结合GAN如何?
- 弱水三千,只取你标!AL(主动学习)结合GAN如何?
- 【1】GAN在医学图像上的生成,今如何?
- 英伟达few-shot图像转换
- 【图像上色小综述】生成对抗网络的GAN法
- 文字生成图像!GAN生成对抗网络相关论文大汇总
发布于 2021-03-01 21:52
