
一、监督学习
有标注数据的学习
1.迁移学习(Transfer learning)
迁移学习(Transfer learning) 顾名思义就是把已训练好的模型(预训练模型)参数迁移到新的模型来帮助新模型训练。
是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。通常,源领域数据量充足,而目标领域数据量较小。
二、非监督学习
无标注数据的学习
三、半监督学习
既有标注数据、又有非标注数据的学习。
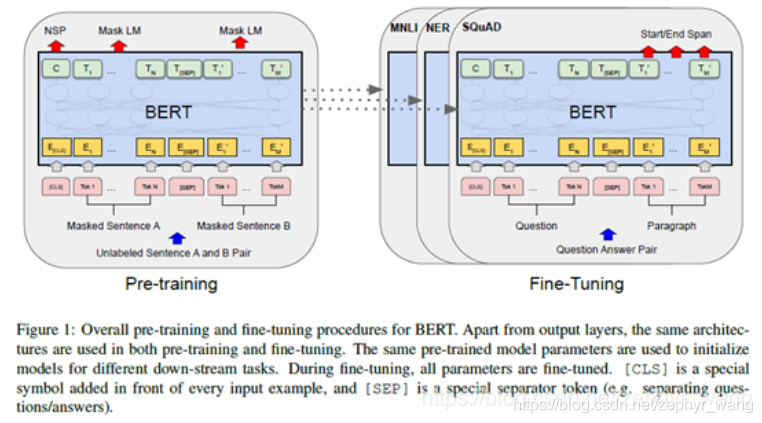
1.预训练pretraining
在NLP领域,比如BERT,先在大量的非标注数据上学习(预训练pretraining),然后再在相应的任务上、相应的标注数据上学习(fine-tune)。
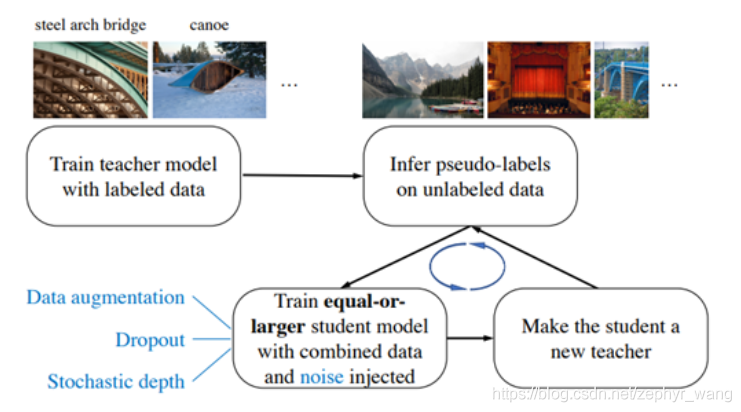
2.自训练Self-training
首先是一个teacher模型在标注数据上训练;
然后使用训练后的teacher对未标注数据进行标注,生成伪标签(合成标签);
最后采用合成标签训练student模型。student模型的大小和teacher相似,或者更大。
有的自训练甚至训练多次迭代,将训练好的student继续作为teacher生成伪标签,又训练一个student模型。
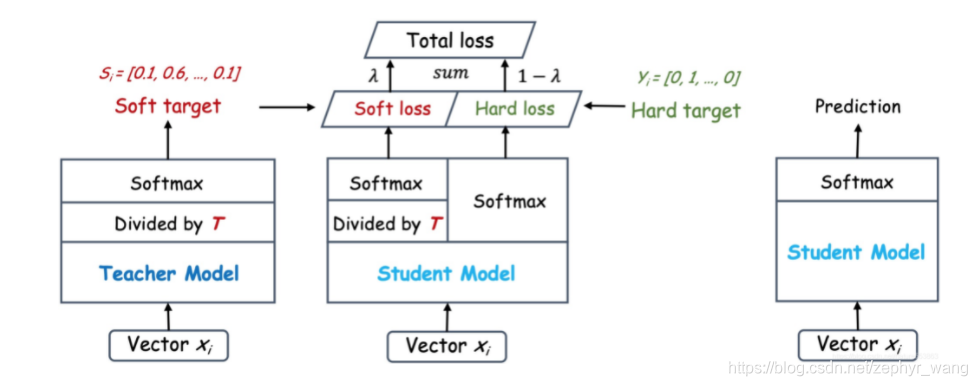
3.知识蒸馏knowledge distillation
Hinton的文章"Distilling the Knowledge in a Neural Network"首次提出了知识蒸馏(暗知识提取)的概念,通过引入与教师网络(teacher network:复杂、但推理性能优越)相关的软目标(soft-target)作为total loss的一部分,以诱导学生网络(student network:精简、低复杂度)的训练,实现知识迁移(knowledge transfer)。
student模型往往比teacher模型小很多。
————————————————
版权声明:本文为CSDN博主「zephyr_wang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zephyr_wang/article/details/119649619
