
Knowledge distillation
Knowledge distillation (KD), also known as model distillation (MD), is an impressive neural network training method proposed by the God Father of deep learning, Geoffrey Hinton, to gain neural network’s performances. If you have never heard about KD, you can reach my post via this link.
Shortly, the core idea of KD is to distill knowledge from a large model (teacher) or an ensemble of neural network models and use that knowledge as soft labels to guide (train) a smaller neural network (student) so that the student can learn more efficiently thereby improving its performance, which can not be achieved by training the student from scratch.
Despite the promising potency of KD, it has a limitation in the training phase because it needs a large resource of hardware and a long time for training a large teacher model or a cumbersome ensemble of models to achieve the goal of generating good pseudo labels (soft labels) for guiding the student model. To this end, Ilija Radosavovic, Kaiming He et al. from Facebook AI Research (FAIR) have proposed Data Distillation which applies semi-supervised learning to improve the performance of CNNs in object detection by utilizing a limited amount of labeled data and the internet-scale amount of unlabeled data. You can easily find the full paper on arXiv.
Data Distillation
Data Distillation vs Knowledge distillation
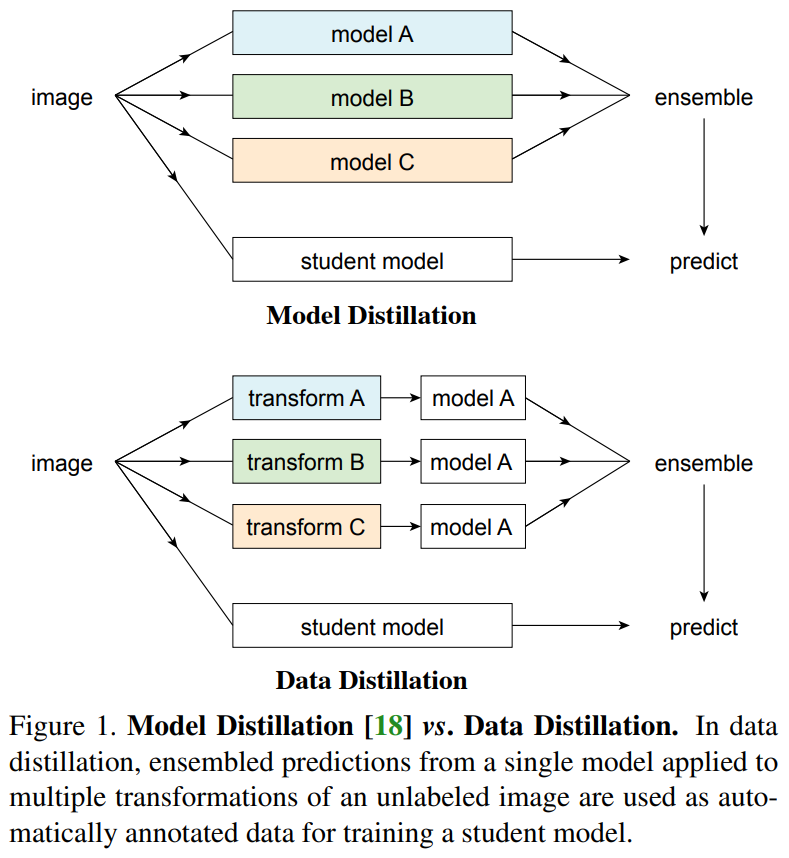
The above figure compares the difference between Data Distillation and Model Distillation (Knowledge Distillation). Model Distillation utilizes an ensemble of models A, B, C to generate soft labels that afterward are used to train the student model. Each model in the ensemble can be larger than or equal to the student model. A popular way to deploy Model Distillation is to train each model independently which is time-consuming and computationally inefficient.
Alternatively, Data Distillation trains only one teacher model A, then applies multi-transform inference to synthesize pseudo labels. Multi-transform inference can be considered to be somewhat similar to the test-time augmentation procedure and it can be applied to improve the performance of neural networks. Multi-transform inference is also a simple manner that requires neither loss function modification nor any model architecture change. In addition, retraining a model on its own prediction on a single-transform image usually does not bring much value in improving performance. Therefore, multiple geometric transformations of the input can help to generate good pseudo labels for training the student model.

How to Perform Data Distillation
Data Distillation involves 4 main steps:
- Train a model on labeled data (like supervised learning)
- Make predictions on multiple transformations of unlabeled data using the trained model
- Ensemble the predictions to generate pseudo labels of unlabeled data
- Retrain the model on the union of the true labels and the pseudo labels until convergence
To clarify, I am giving an example of how to deploy Data Distillation for object detection with YOLOv4.
- First, train YOLOv4 on a set of label data like conventional supervised learning.
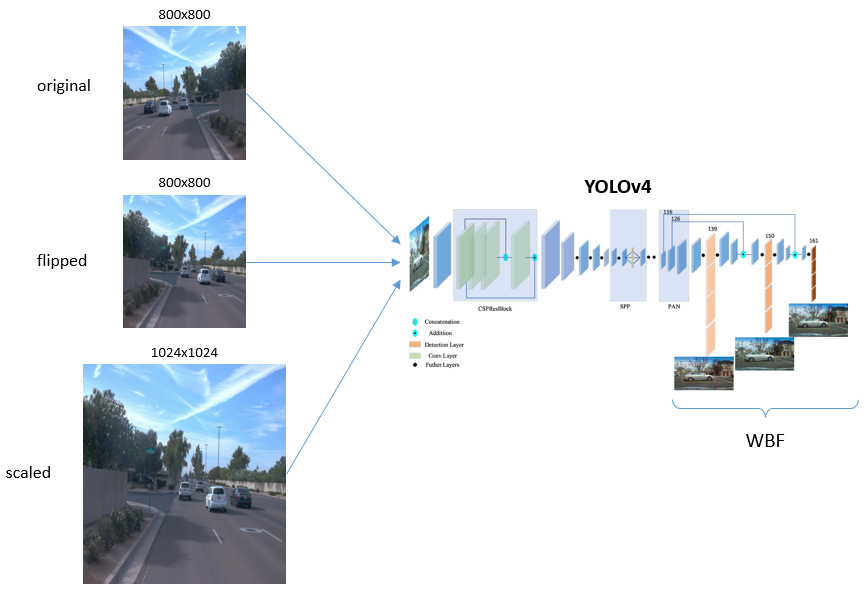
- After that, use the trained YOLOv4 to make predictions on multiple geometry transformations of unlabeled data, as in the figure below, I apply an original image, a flipped version, and an upscaled version just like the test-time augmentation procedure.
- Then, the output will be processed by adopting Weighted Box Fusion (WBF) method, you can apply any bounding box post-processing method here, e.g. non-maximum suppression. We all know that the output always includes true positive, false positive, and false negative; and we have to select “good” predictions for pseudo labels. A simple but effective manner is to pick the predictions with confidence scores higher than a certain threshold. And how to choose a threshold? In the paper, the authors utilized a threshold that makes the average number of objects in an unlabeled image equal to that of a true label image. This may not valid in all cases but at least it works!
- At last, combine the true labeled data and the generated pseudo labeled data to retrain (or fine-tune) the YOLOv4 model.
Results on Object Detection
The performance of Data Distillation on the benchmark dataset COCO is given in the paper. I would like to summarize it as follows:
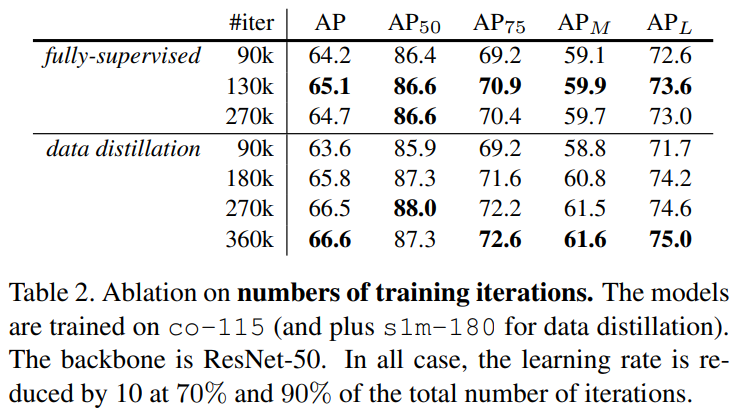
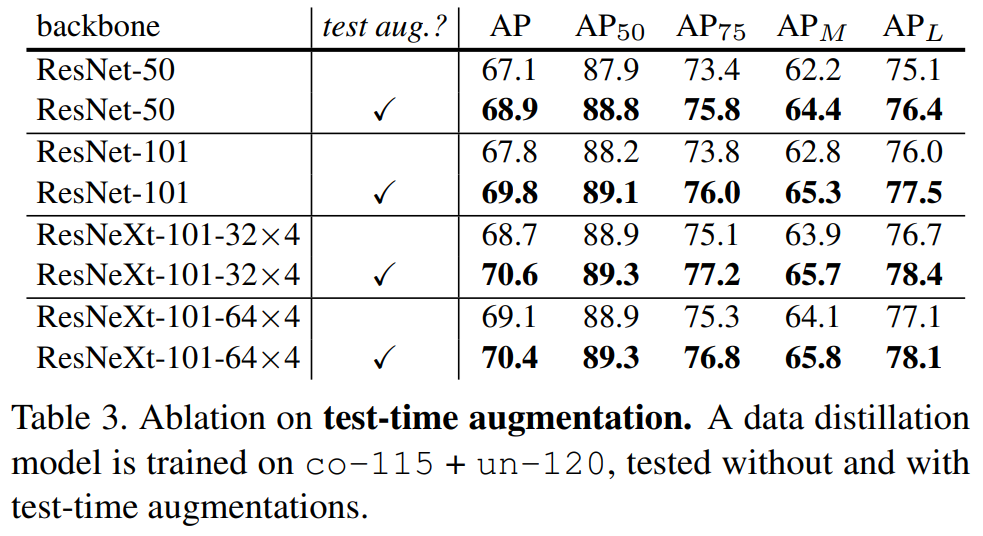

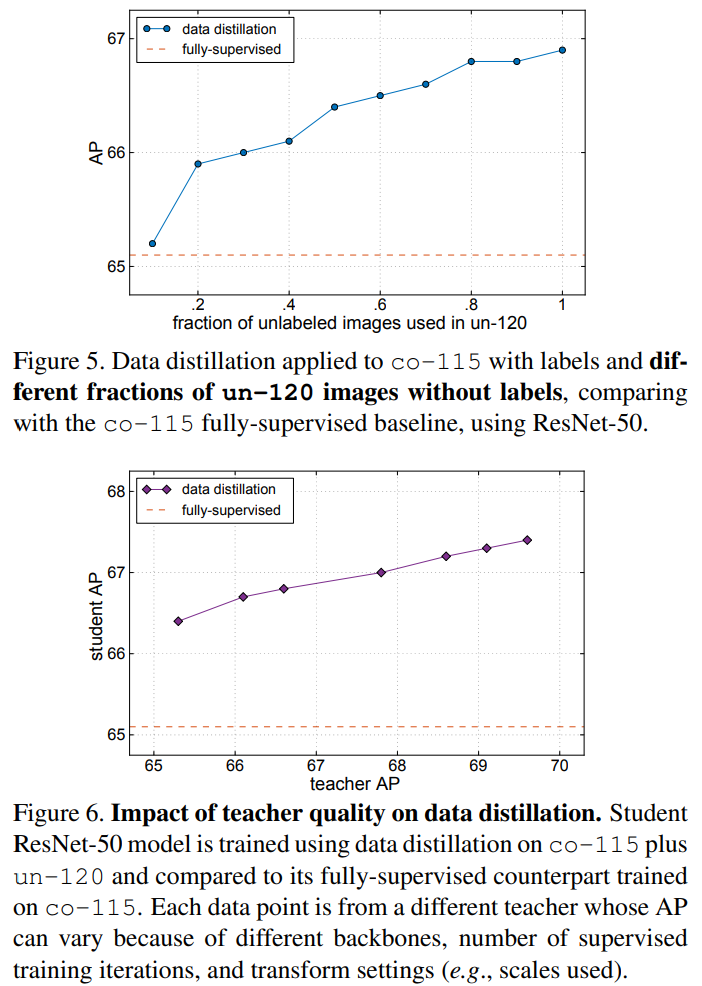

For further details, you can read the full paper.
Conclusions
In this post, I have briefly reviewed Data Distillation, a semi-supervised learning method for improving the performance of CNNs. By utilizing multiple geometric transformations of unlabeled data, the method generates high-quality pseudo labels that can be combined with the manually labeled data in order to improve the learning efficiency of a neural network model. The potency of Data Distillation has been validated on benchmark datasets of human keypoint detection and object detection tasks.
from: https://towardsdatascience.com/data-distillation-for-object-detection-92a89fe5d996
